---
title: Registration
code-fold: true
params:
csv_dir: "private/csv"
registration_fn: "registrations-2026.csv"
presenters_fn: "presenters-2026.csv"
sheets_fn: "Open Scholarship Bootcamp 2026: Registration (Responses)"
reg_sheets_id: "1mM0rSuFS5_y2sQtU9AI9zm8kuOGeDzilJZdu1MUR8zk"
psu_id: "rog1@psu.edu"
---
## About
This page documents and implements the data processing workflow for bootcamp registration.
## Setup
We load some packages into memory for convenience.
```{r}
#| label: load-packages
suppressPackageStartupMessages(library('tidyverse'))
suppressPackageStartupMessages(library('ggplot2'))
suppressPackageStartupMessages(library('dplyr'))
suppressPackageStartupMessages(library('tidyr'))
suppressPackageStartupMessages(library('stringr'))
suppressPackageStartupMessages(library('lubridate'))
suppressPackageStartupMessages(library('janitor'))
```
## Import
The Google Form generates a Google Sheet that we download to a protected directory (`private/csv`) that is *not* synched to GitHub.
::: {.callout-important}
This is because the sheet contains personally identifying information.
To implement this, we add `private` to our `.gitignore` file in the project's root directory. This omits all files in `private/` from version control and keeps them local to the machine we render the site from.
:::
```{r}
#| label: import-data
#| message: false
#|
x <- assertthat::is.string(params$csv_dir)
if (!dir.exists(params$csv_dir)) {
message("Creating missing `include/csv/`.")
dir.create(params$csv_dir)
}
x <- assertthat::is.writeable(params$csv_dir)
# options(gargle_oauth_email = Sys.getenv("GMAIL_SURVEY"))
# googledrive::drive_auth()
x <- assertthat::is.string(params$psu_id)
googlesheets4::gs4_auth(email = params$psu_id)
x <- assertthat::is.string(params$sheets_id)
registrations <- googlesheets4::read_sheet(params$reg_sheets_id,
sheet = "Form Responses 1")
x <- assertthat::assert_that(is_tibble(registrations))
registration_full_fn <- file.path(params$csv_dir, params$registration_fn)
x <- assertthat::is.string(registration_full_fn)
readr::write_csv(registrations, file = registration_full_fn)
```
Download presenter data, too.
```{r}
#| label: download-save-program-committee
#| message: false
presenters <- googlesheets4::read_sheet(params$reg_sheets_id,
sheet = "presenters")
x <- assertthat::assert_that(is_tibble(presenters))
x <- assertthat::is.string(params$presenters_fn)
presenters_full_fn <- file.path(params$csv_dir, params$presenters_fn)
readr::write_csv(presenters, file = presenters_full_fn)
```
## Clean
Google Forms conveniently returns the questions as variable names at the top of each column. These are handy for creating a data dictionary, but awkward for data processing. We rename these for our convenience.
```{r}
#| label: tbl-data-dictionary
#| tbl-cap: "A minimal data dictionary."
reqistrations_qs <- names(registrations)
registrations_clean <- registrations |>
dplyr::rename(
timestamp = "Timestamp",
attend_days = "Which days of the bootcamp will you attend?",
name = "What is your name?",
email = "Email Address",
dept = "What is your department or unit?",
position = "What is your current position?",
comments = "Any comments?",
dropped_out = "drop-out"
)
registrations_short <- c(
"timestamp",
"email",
"attend_days",
"name",
"dept",
"position",
"comments",
"dropped_out"
)
```
We also export a data dictionary.
```{r}
registrations_pid <- c(FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE)
registrations_dd <- data.frame(qs = reqistrations_qs,
qs_short = registrations_short,
pid = registrations_pid)
registrations_dd |>
knitr::kable(format = 'html')
data_dict_fn <- file.path(params$csv_dir, "registrations-2026-data-dict.csv")
x <- assertthat::is.string(data_dict_fn)
readr::write_csv(registrations_dd,
file = data_dict_fn)
```
We drop some of responses that were used to test the workflow or who are presenters.
```{r}
registrations_clean <- registrations_clean |>
dplyr::filter(email != "nittany.amateur.radio.club@gmail.com")
registrations_clean <- registrations_clean |>
dplyr::filter(name != "Koraly Pérez-Edgar") |>
dplyr::filter(name != "Carrie Brown")
registrations_clean <- registrations_clean |>
dplyr::mutate(name = if_else(name == "Maria A Sanchez Farran", "Maria Sanchez Farran", name))
```
We normalize the `dropped_out` variable.
```{r}
registrations_clean <- registrations_clean |>
dplyr::mutate(dropped_out = if_else(is.na(dropped_out), FALSE, TRUE))
```
And normalize the presenter names.
```{r}
presenters_clean <- janitor::clean_names(presenters)
```
## Visualize
### Registration numbers {-}
```{r}
#| label: create-subsetted-dfs
attendees_names <- registrations_clean$name
presenter_names <- presenters$name
all_names <- unique(c(attendees_names, presenter_names))
n_all <- length(all_names)
n_drop_outs <- sum(registrations_clean$dropped_out)
```
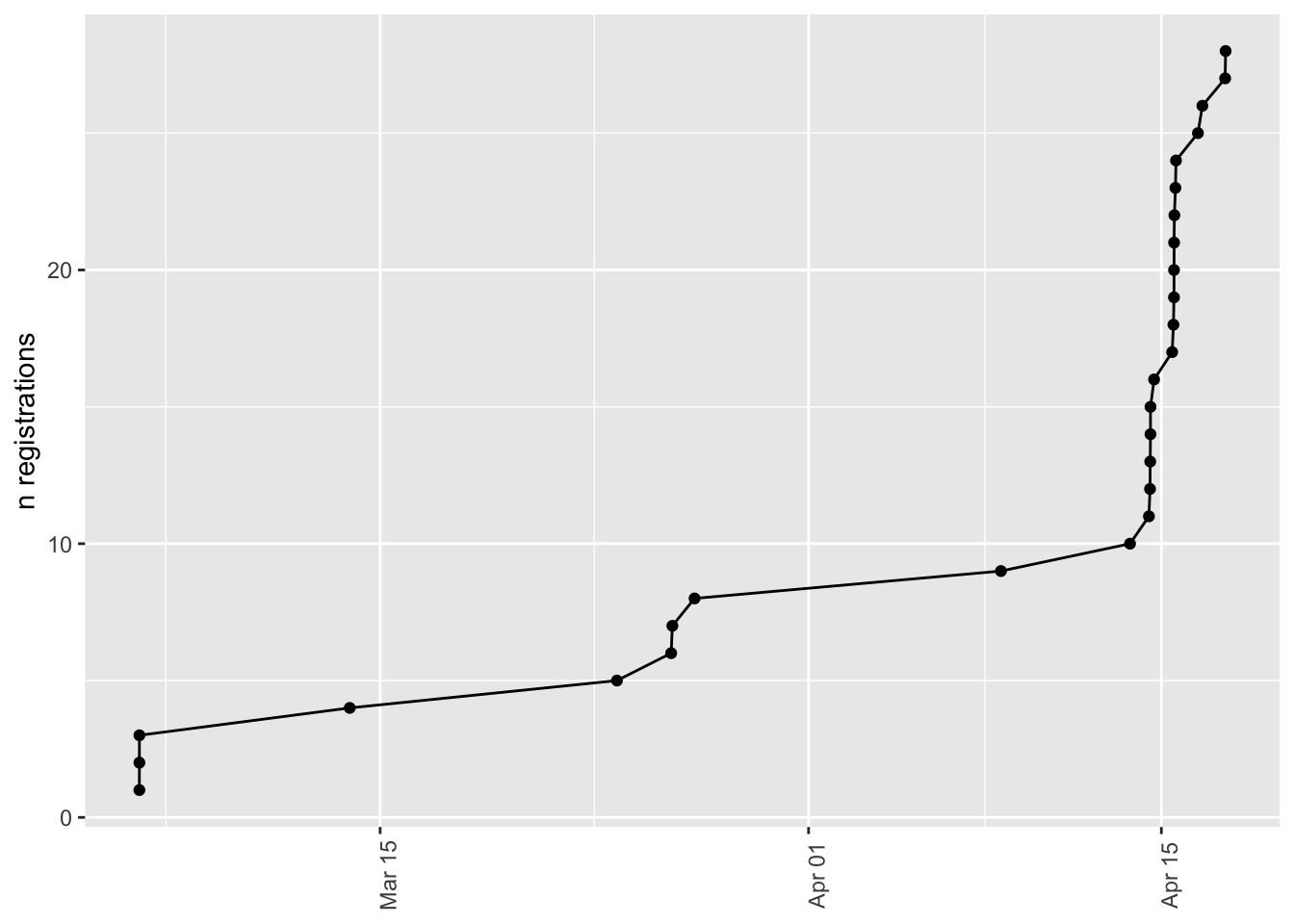
As of `r Sys.Date()`, we have *n*=`r dim(registrations_clean)[1]` registered attendees. We also have *n*=`r length(presenter_names)` presenters. A handful of presenters also registered. Some people registered twice, and *n* = `r n_drop_outs` have had to cancel, so we have *n*=`r n_all - n_drop_outs` unique attendees who plan to come.
That is `r round(100*(n_all - n_drop_outs)/75, 1)`\% of our target registration/attendance target of *n*=75.
### Time series {-}
```{r}
#| label: fig-registration-time-series
#| fig-cap: "Time series of registrations."
registrations_clean |>
dplyr::arrange(timestamp) |>
dplyr::mutate(resp_index = seq_along(timestamp)) |>
ggplot() +
aes(x = timestamp, y = resp_index) +
geom_point() +
geom_line() +
theme(axis.text.x = element_text(angle = 90)) +
labs(x = NULL, y = 'n registrations') +
theme(legend.position = "none")
```
<!-- ### Registrant attendance plans by day -->
<!-- ```{r} -->
<!-- #| label: tbl-registration-by-day -->
<!-- #| fig-cap: "Bootcamp registrations by day." -->
<!-- registrations_clean |> -->
<!-- dplyr::mutate(plan_mon = stringr::str_detect(attend_days, "Mon"), -->
<!-- plan_tue = stringr::str_detect(attend_days, "Tue")) |> -->
<!-- dplyr::mutate(n_mon = sum(plan_mon, na.rm = TRUE), -->
<!-- n_tue = sum(plan_tue, na.rm = TRUE)) |> -->
<!-- dplyr::select(n_mon, n_tue) |> -->
<!-- dplyr::distinct() |> -->
<!-- knitr::kable(format = "html") |> -->
<!-- kableExtra::kable_classic() -->
<!-- ``` -->
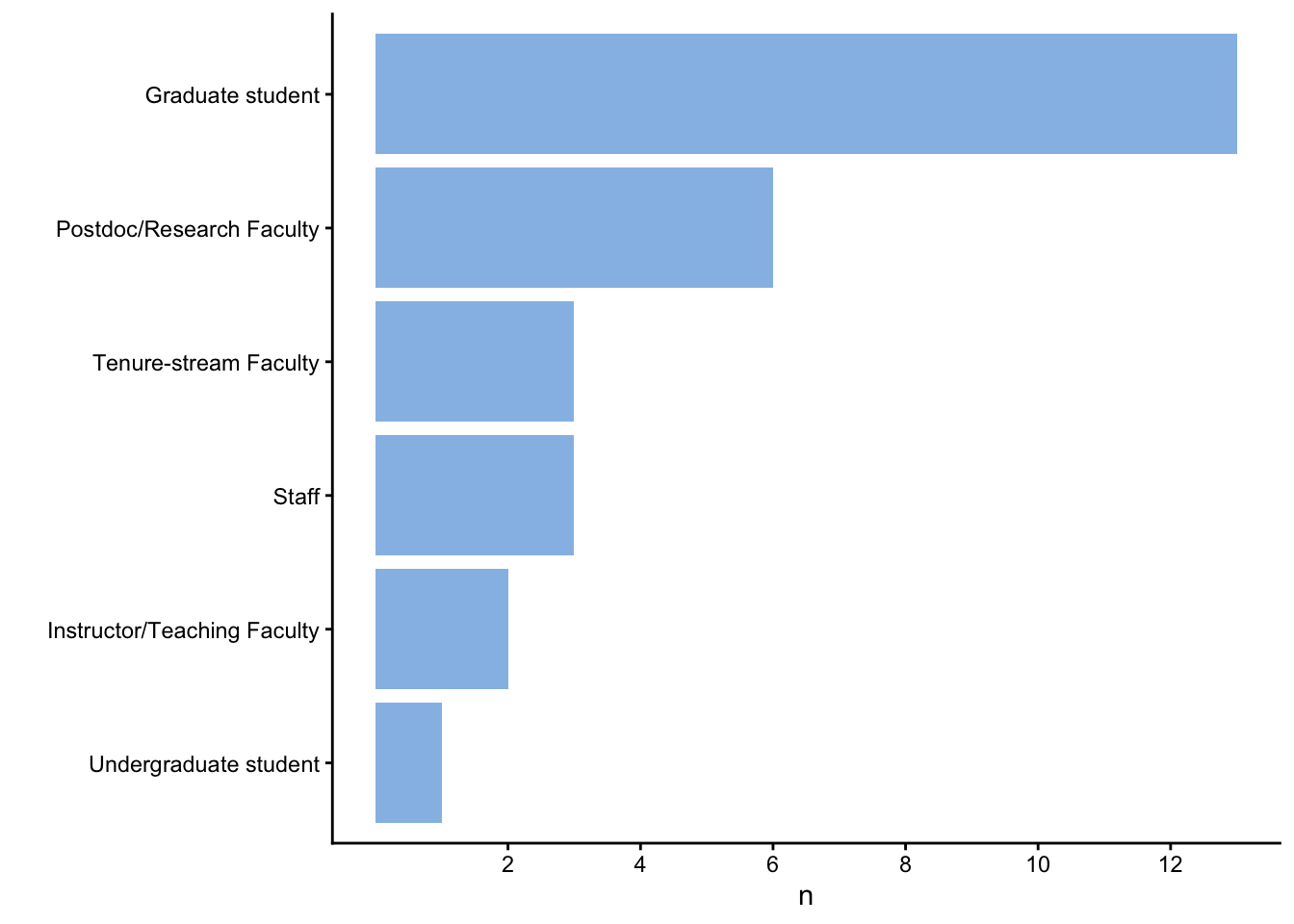
### Registrations by position
```{r}
#| label: fig-by-position
#| fig-cap: "Registrations by position."
registrations_clean |>
dplyr::filter(!is.na(position)) |>
dplyr::count(position, sort = TRUE) |>
dplyr::mutate(position = fct_reorder(position, n)) |>
ggplot() +
geom_bar(aes(x = position, y = n), fill = "#96BEE6", stat = "identity") +
scale_y_continuous(breaks = seq(0, 50, by = 5)) +
theme(legend.position = "right") +
theme(legend.title = element_blank()) +
xlab("") +
theme_classic() +
coord_flip()
```
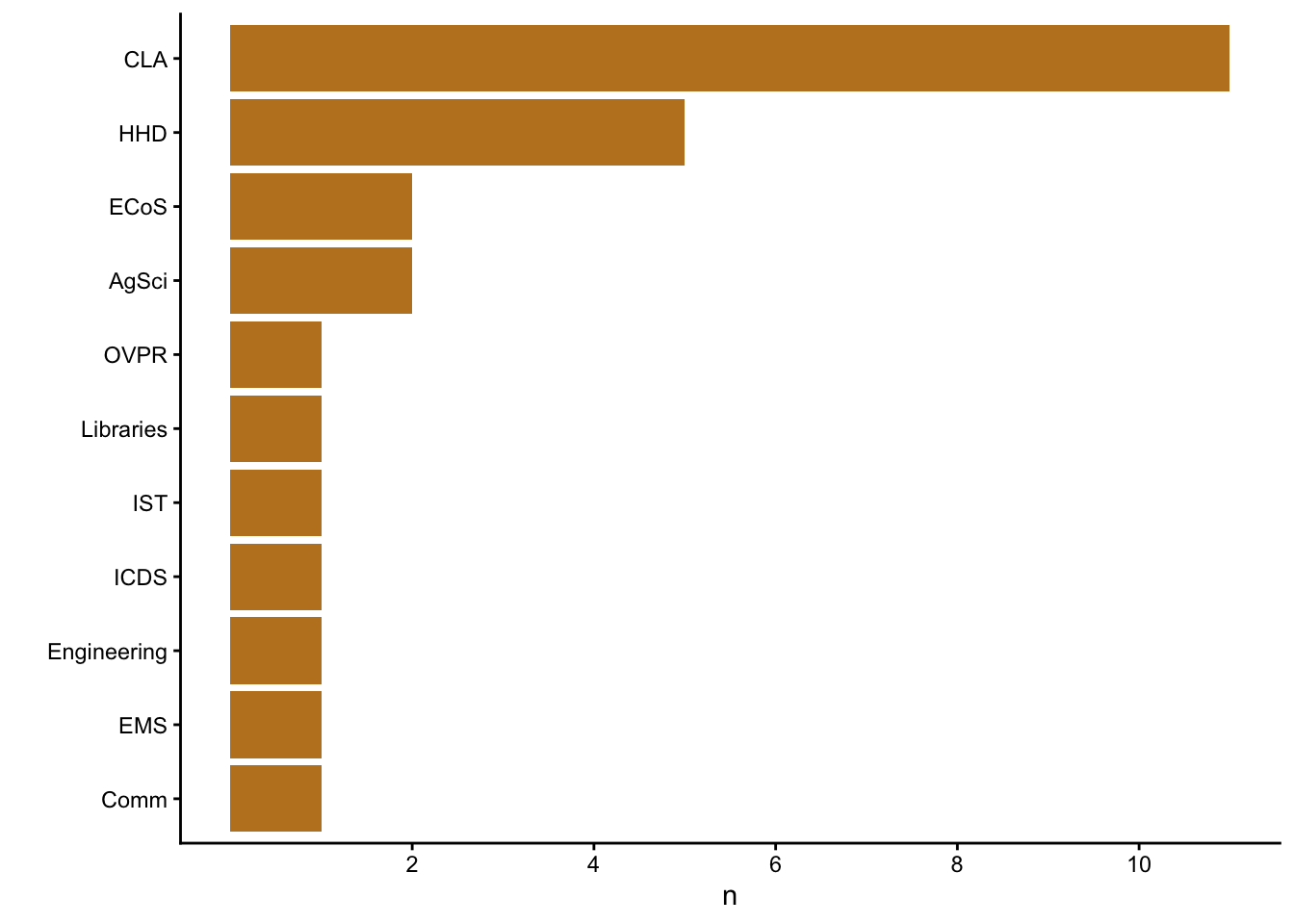
### Registrations by unit
Clean and recode.
```{r}
select_this <- registrations_clean$name == "Parisa Osfoori"
registrations_clean$dept[select_this] <- "Communication Sciences & Disorders"
select_this <- registrations_clean$name == "Koraly Pérez-Edgar"
registrations_clean$dept[select_this] <- "Psychology"
select_this <- registrations_clean$name== "Keyana Enayati"
registrations_clean$dept[select_this] <- "PSU Harrisburg"
```
Normalize department names; assign college/institute values.
```{r by-dept}
registrations_clean <- registrations_clean |>
dplyr::mutate(
dept = dplyr::recode(
dept,
`Clinical Psychology` = "Psychology",
`Psychology (Cognitive)` = "Psychology",
`Psychology / SSRI` = "Psychology",
`Psychology (Developmental)` = "Psychology",
`Department of Psychology` = "Psychology",
`Cognitive Psychology` = "Psychology",
`Psychology, Developmental` = "Psychology",
`Developmental Psychology (CAT Lab)` = "Psychology",
`Developmental Psychology` = "Psychology",
`Psych` = "Psychology",
`College of Liberal Arts (psychology)` = "Psychology",
`English language` = "English",
`english` = "English",
`English Language Teaching` = "English",
`English Department` = "English",
`Languages` = "Global Languages & Literatures",
`Languages and Literature` = "Global Languages & Literatures",
`Department of Foreign Languages` = "Global Languages & Literatures",
`Linguistics` = "Applied Linguistics",
`Department of Sociology and Criminology` = "Sociology & Criminology",
`Communication Arts and Sciences` = "Communication Arts & Sciences",
`Communication Sciences and Disorders` = "Communication Sciences & Disorders",
`CSD` = "Communication Sciences & Disorders",
`Human Development and Family Studies & Social Data Analytics` = "HDFS",
`Human Development and Family Studies` = "HDFS",
`Human Development and Family Studies (HDFS)` = "HDFS",
`Department of Human Development and Family Studies` = "HDFS",
`Human Development and Family Sciences` = "HDFS",
`HDFS/DEMO` = "HDFS",
`bbh` = "BBH",
`Biobehavioral Health` = "BBH",
`Biobehavioural Health` = "BBH",
`Biobehavioural Health` = "BBH",
`Biobehavioral health` = "BBH",
`RPTM` = "Recreation, Park, & Tourism Management",
`Recreation, Park and Tourism Management` = "Recreation, Park, & Tourism Management",
`Sociology and Social Data Analytics` = "Sociology",
`Spanish Italian and portuguese` = "Spanish, Italian, & Portuguese",
`Spanish, Italian, and Portuguese Department` = "Spanish, Italian, & Portuguese",
`Spanish Italian and Portuguese` = "Spanish, Italian, & Portuguese",
`Spanish, Italian, and Portuguese` = "Spanish, Italian, & Portuguese",
`French and Francophone Studies` = "French & Francophone Studies",
`DEMOG` = "Demography",
`Germanic & Slavic Languages & Literatures` = "German & Slavic Languages",
`Germanic and Slavic Languages and Literatures` = "German & Slavic Languages",
`Nutrition` = "Nutritional Sciences",
`Department of Nutritional Sciences` = "Nutritional Sciences",
`Nurition` = "Nutritional Sciences",
`College of IST` = "IST",
`Statistics Department` = "Statistics",
`Department of Statistics` = "Statistics",
`stat` = "Statistics",
`statistic` = "Statistics",
`Math` = "Mathematics",
`Astronomy and Astrophysics` = "Astronomy & Astrophysics",
`SHS` = "Student Health Svcs",
`Department of Chemical Engineering` = "Chemical Engineering",
`ESM` = "Engineering Science & Mechanics",
`Engineering Science` = "Engineering Science & Mechanics",
`Engineering Science and Mechanics` = "Engineering Science & Mechanics",
`EECS` = "Electrical Engineering & Comp Sci",
`Department of Food Science` = "Food Science",
`Libraries` = "University Libraries",
`University libraries` = "University Libraries",
`Ecosystem Science and Management` = "Ecosystem Science & Management",
`PRC` = "Population Research Center",
`TLT, PSU Libraries` = "University Libraries",
`Business and Economics` = "Business & Economics",
`EE` = "Electrical Engineering",
`College of Medicine / Clinical and Translational Science Institute` = "CTSI",
`College of Medicine, CTSI` = "CTSI",
`Mechanical engineering,Penn state Harrisburg` = "Mechanical Engineering (Harrisburg)",
`Smeal College of Business, Accounting` = "Accounting",
`School of Science, Engineering, and Technology` = "Sci, Engr, & Tech",
`institute for Computational and Data Sciences` = "ICDS",
`Plant Pathology and environmental microbiology` = "Plant Pathology & Environmental Microbiology",
`Meteorology and Atmospheric Sciences` = "Meteorology & Atmospheric Sciences",
`Department of Meteorology and Atmospheric Science` = "Meteorology & Atmospheric Sciences",
`School of Labor and Employment Relations` = "School of Labor & Employment Relations",
`PCD` = "Preservation Conservation & Digitization",
`Vazquez Lab/Eberly College of Science/Bio` = "Biology",
`Biology Department/ Vazquez lab` = "Biology",
`WORKFORCE EDUCATION AND DEVELOPMENT` = "Workforce Education & Development",
`Curriculum and Instructions` = "Curriculum & Instruction",
`Kinesiology, HHD` = "Kinesiology",
`BME` = "Biomedical Engineering",
`Computer Science` = "Computer Science & Engineering",
`Department of Computer Science and Engineering` = "Computer Science & Engineering",
`College of Engineering/Computer Science` = "Computer Science & Engineering",
`Ed Policy Studies` = "Education Policy Studies",
`CHE` = "Chemical Engineering",
`Agricultural and Biological Engineering` = "Agricultural & Biological Engineering",
`Mechanical` = "Mechanical Engineering",
`Health Administration` = "Health Policy & Administration",
`CMPEN` = "Computer Engineering",
`ESM/ REI` = "Engineering Science & Mechanics",
`Civil Eng` = "Civil Engineering",
`Meteorology and Atmospheric Science` = "Meteorology & Atmospheric Science",
`Meteorology and Atmospheric Sciences` = "Meteorology & Atmospheric Science",
`Department of Meteorology and Atmospheric Science` = "Meteorology & Atmospheric Science",
`Meteorology & Atmospheric Sciences` = "Meteorology & Atmospheric Science"
)
) |>
dplyr::mutate(
college = recode_values(
dept,
"Agricultural & Biological Engineering" ~ "AgSci",
"Ecosystem Science & Management" ~ "AgSci",
"Entomology" ~ "AgSci",
"Food Science" ~ "AgSci",
"Plant Pathology & Environmental Microbiology" ~ "AgSci",
"Plant Science" ~ "AgSci",
"German & Slavic Languages" ~ "CLA",
"Psychology" ~ "CLA",
"Spanish, Italian, & Portuguese" ~ "CLA",
"Anthropology" ~ "CLA",
"Applied Linguistics" ~ "CLA",
"Asian Studies" ~ "CLA",
"C-SoDA" ~ "CLA",
"Demography" ~ "CLA",
"Communication Arts & Sciences" ~ "CLA",
"Economics" ~ "CLA",
"English" ~ "CLA",
"French & Francophone Studies" ~ "CLA",
"Global Languages & Literatures" ~ "CLA",
"Office of Digital Pedagogies and Initiatives" ~ "CLA",
"Political Science" ~ "CLA",
"Sociology" ~ "CLA",
"Sociology & Criminology" ~ "CLA",
"School of Labor & Employment Relations" ~ "CLA",
"Bellisario College of Communication" ~ "Comm",
"Mass Communications" ~ "Comm",
"Astronomy & Astrophysics" ~ "ECoS",
"Biology" ~ "ECoS",
"Chemistry" ~ "ECoS",
"Integrative Science" ~ "ECoS",
"Mathematics" ~ "ECoS",
"Statistics" ~ "ECoS",
"College of Education" ~ "Education",
"LPS/LDT" ~ "Education",
"Workforce Education & Development" ~ "Education",
"Curriculum & Instruction" ~ "Education",
"Education Policy Studies" ~ "Education",
"Meteorology & Atmospheric Science" ~ "EMS",
"Meteorology & Atmospheric Sciences" ~ "EMS",
"Acoustics" ~ "Engineering",
"Biomedical Engineering" ~ "Engineering",
"Chemical Engineering" ~ "Engineering",
"Chemical/Biomedical Engineering" ~ "Engineering",
"Civil Engineering" ~ "Engineering",
"College of Engineering" ~ "Engineering",
"Computer Engineering" ~ "Engineering",
"Computer Science & Engineering" ~ "Engineering",
"Electrical Engineering & Comp Sci" ~ "Engineering",
"Electrical Engineering" ~ "Engineering",
"Engineering" ~ "Engineering",
"Engineering Science & Mechanics" ~ "Engineering",
"Material Science and Engineering" ~ "Engineering",
"Mechanical Engineering" ~ "Engineering",
"College of Human and Health Development" ~ "HHD",
"Communication Sciences & Disorders" ~ "HHD",
"BBH" ~ "HHD",
"HDFS" ~ "HHD",
"Kinesiology" ~ "HHD",
"Nutritional Sciences" ~ "HHD",
"Recreation, Park, & Tourism Management" ~ "HHD",
"HHD" ~ "HHD",
"Health Policy & Administration" ~ "HHD",
"Biotechnology" ~ "Huck",
"Plant Biology" ~ "Huck",
"ICDS" ~ "ICDS",
"IST" ~ "IST",
"Data Analytics" ~ "IST",
"Cybersecurity" ~ "IST",
"Information Science and Technology" ~ "IST",
"Preservation Conservation & Digitization" ~ "Libraries",
"Research Informatics and Publishing" ~ "Libraries",
"University Libraries" ~ "Libraries",
"Neuroscience" ~ "Medicine",
"Medicine" ~ "Medicine",
"CTSI" ~ "Medicine",
"College of Nursing" ~ "Nursing",
"EESI" ~ "EESI",
"Psychology (Harrisburg)" ~ "PSU Harrisburg",
"PSU Harrisburg" ~ "PSU Harrisburg",
"Mechanical Engineering (Harrisburg)" ~ "PSU Harrisburg",
"PSU Harrisburg" ~ "PSU Harrisburg",
"Sci, Engr, & Tech" ~ "PSU Harrisburg",
"Business & Economics" ~ "PSU Brandywine",
"Schreyer Institute for Teaching Excellence" ~ "Old Main",
"OVPR" ~ "OVPR",
"ORP" ~ "OVPR",
"Population Research Center" ~ "SSRI",
"Accounting" ~ "Smeal",
"Marketing" ~ "Smeal",
"University of Kansas, Psychology" ~ "UKansas"
),
.default = "Unknown",
.missing = "Unknown"
)
```
Plot.
```{r}
#| label: fig-regis-dept-coll
#| fig-cap: "Registrations by college/unit."
registrations_clean |>
dplyr::filter(!is.na(college)) |>
dplyr::count(college, sort = TRUE) |>
dplyr::mutate(college = fct_reorder(college, n)) |>
ggplot() +
geom_bar(aes(x = college, y = n), fill = "#BF8226", stat = "identity") +
scale_y_continuous(breaks = seq(2, 24, by = 2)) +
theme(legend.position = "right") +
theme(legend.title = element_blank()) +
xlab("") +
theme_classic() +
coord_flip()
```
The bootcamp registrations represent *n*=`r length(unique(registrations_clean$dept))` departments and *n*=`r length(unique(registrations_clean$college))` campuses, colleges, institutes, or administrative entities.
### Save cleaned files
```{r}
readr::write_csv(registrations_clean, file.path(params$csv_dir, "registrations-2026-clean.csv"))
readr::write_csv(presenters_clean, file.path(params$csv_dir, "presenters-2026-clean.csv"))
```