|
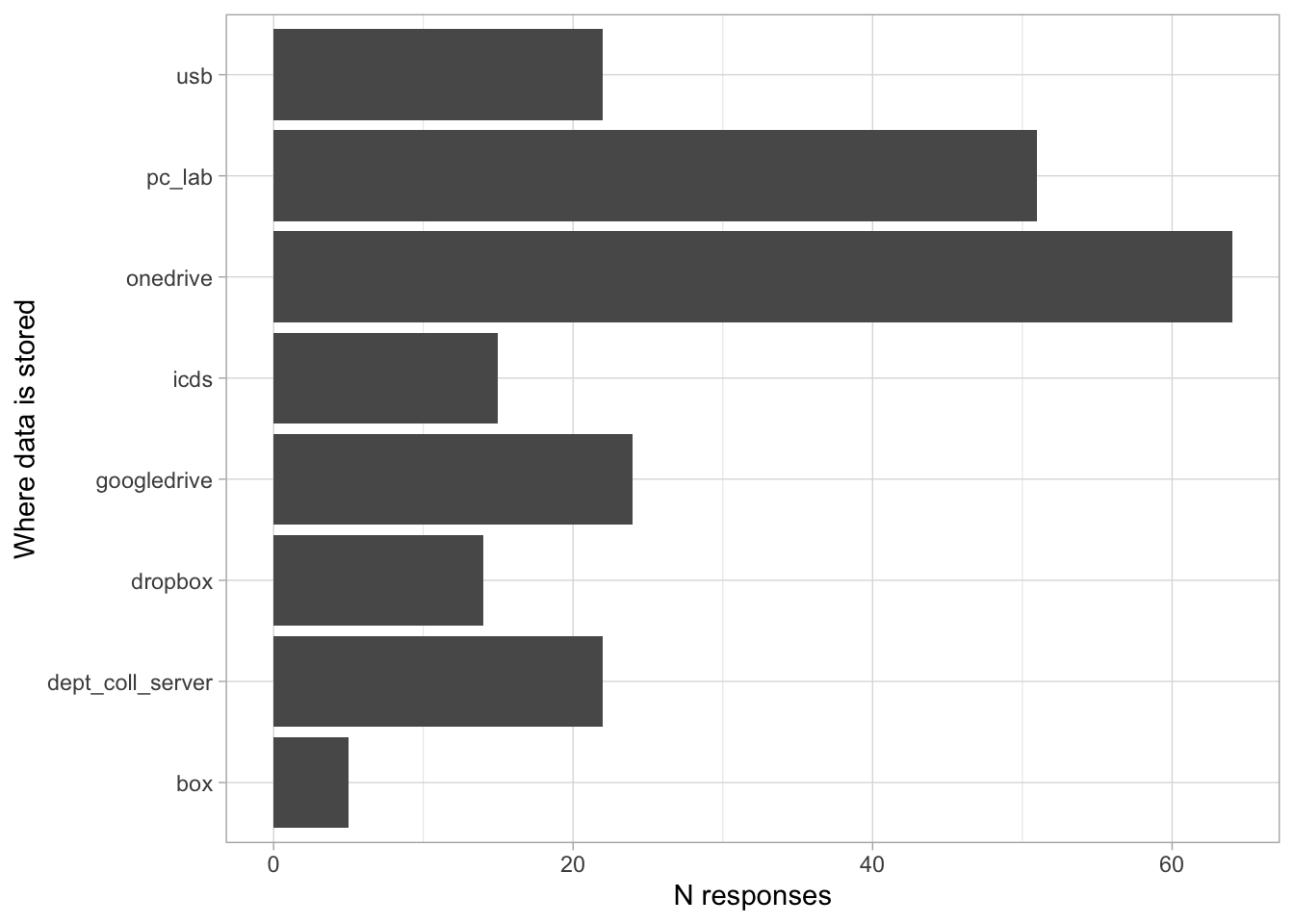
Different people use different ways of sharing/storing data (Box, Dropbox, Github, Drive, etc.)
|
|
getting access approved for external users
|
|
ensuring that users adhere to data security and the time required to prepare data sets for sharing
|
|
Lots of different file types, collaborators not used to using file structure/naming structure
|
|
I need to use dropbox since nobody has box or one drive at other institutions.
|
|
Onedrive has a bizarre sharing UI. I am starting to understand it but it is quite counterintuitive compared to google drive
|
|
Getting permissions correctly established on the ICDS system. Adding members on ICDS. Getting liberal arts computers to communicate with ICDS systems (i.e., mapping drives). For whatever reason this seems to take days-weeks, every time we have a new person.
|
|
Creating clean public use files and clear documentation.
|
|
Access to different platforms that might not allow colleagues at other universities to access the data
|
|
No technological or legal barriers. But sharing is not always necessary or desirable prior to a project’s completion, so the barrier (if you could call it that) is one deliberately created by me as researcher.
|
|
size
|
|
The ethical approvals required and the types of data that can be shared. I think things are getting better since we are learning how to share these types of data
|
|
having a shared box outside people can access that is not a Google drive
|
|
There are no barriers; my data is publicly available and if it goes missing / gets deleted I share the backups I make with collaborators.
|
|
Sharing legal administrative data and PII are difficult
|
|
na
|
|
Getting them on OneDrive if they are not already using it
|
|
None really.
|
|
N/A
|
|
When my collaborators are outside of Penn State sometimes they have challenges to log in to OneDrive.
|
|
No big barriers. Email etc. is fine when needed.
|
|
OneDrive can be confusing; sometimes hard to share with people outside of PSU
|
|
Data organization - When you share a folder, the person who receives it is unable to organize that folder within their system in the place they want it to appear. So, I have a large list of shared folders, none of which are organized in a way that makes sense to me.
|
|
File size and collaborators’ lack of access to/use of OneDrive
|
|
That PSU changes from Box to One Drive to Fill-In-The-Blank on a semi-frequent basis.
|
|
IRB
|
|
Tools that make it easy. We fight with Globus (and it doesn’t work for some other partner Universities) and using NCBI SRA database is clunky, with limited metadata entry that can occur.
|
|
Large file sizes and PSU’s data security protocols
|
|
office of sponsored projects/legal places unreasonable restrictions on data sharing and data in general; their default is to be hypercautious and treat all data as if it were highly sensitive; for convincing them otherwise, the process takes MONTHS. This is the biggest impediment to human subjects research at PSU. Not IRB. Not our external data providers or collaborators. it is the risk-averse legal/bureaucratic environment at PSU, which is out of line with our peer institutions.
|
|
Not applicable
|
|
It can be cumbersome to make large numbers of image datasets available through globus or by transferring to Sharepoint. Many major collaborators of ours are set up on ICDS with sponsored accounts, but even then it isn’t always easy to get others set up with globus or access.
|
|
The IRB requirements for data sharing sometimes get in the way
|
|
As an ethnographer, the primary concern is sharing data due to ethical concerns.
|
|
OSF is not user friendly, and there is some concern that materials will be used before we have a chance to get our research published.
|
|
No major barriers. File-sharing and version control software isn’t perfect, but it’s come a long way!
|
|
Analysis of large video datasets is too slow over the web.
|
|
lack of stability- moving from one system to another (Box to Onedrive) causes confusion, wastes time
|
|
None
|
|
my own organization skills; laziness; need for me to spend extra time getting labels and format into shape that others can use
|
|
We often resort to google drives, but I find cloud-based repositories of data often difficult to navigate
|
|
Confidentiality
|
|
Access to PSU server; PSU and IRB changing cloud services and where it is acceptable to house data
|
|
Security of online systems
|
|
Knowing which server to use
|
|
providing collaborators outside Penn State with access to secure Penn State resources like OneDrive/Sharepoint is possible but requires quite a bit of effort. Data use agreements between institutions sometimes take a long time to finalize.
|
|
Getting collaborators access to shared drives or folders (e.g. having to request someone have access to folders on Roar).
|
|
Concerns of deductive disclosure, the time to build the needed infrastructure, time to properly make data FAIR without funds to support it
|
|
Sharing my own data is no problem. It is getting data from others that is difficult.
|
|
Office of Research Protections Human Subject data research restrictions
|
|
Confidentiality
|
|
Penn State changing their storage company too often
|
|
Usability of sharepoint and microsoft drive
|
|
Biggest barrier is to external collaborators
|
|
Regulatory restrictions (e.g. HIPAA, FERPA), and interoperability issues (e.g. ROAR->OneDrive). Plus, just tracking who can access what when data are sensitive in parts, and tracking who has which version of versioned data sets.
|
|
Person time to provide data and documentation
|
|
Granting/maintaining access
|
|
TIME, data management knowledge and skills, versioning and changes after you’ve shared the data, knowing what to share (raw vs. cleaned vs. scored), knowing where to store shared files, participant privacy concerns
|
|
Technical infrastructure that supports a single source of truth for data and metadata
|
|
scale of data
|
|
The Sharepoint file sharing process isn’t fantastic. Links that were created correctly stop working at random times, or permissions change.
|
|
volume of data (few files, large sizes)
|
|
Penn State switching data sharing sources (i.e. Box to One Drive) every couple of years.
|
|
None
|
|
Size of the data
|
|
Sometimes onedrive does not work well for collaborating with institutions outside of penn state.
|
|
If I was a researcher: knowing who to collaborate with, scheduling and timelines with busy collaborators, and some data may not be shared easily (if done electronically).
|
|
the default is that you should not do this
|
|
Understandability
|
|
Interview and survey results have PII
|
|
The microsoft products (OneDrive etc) are much worse than our former Box system. I avoid using them. In contrast, Box was fine. Dropbox also is fine (I have a self-paid Dropbox account I use now since Box was discontinued at PSU).
|
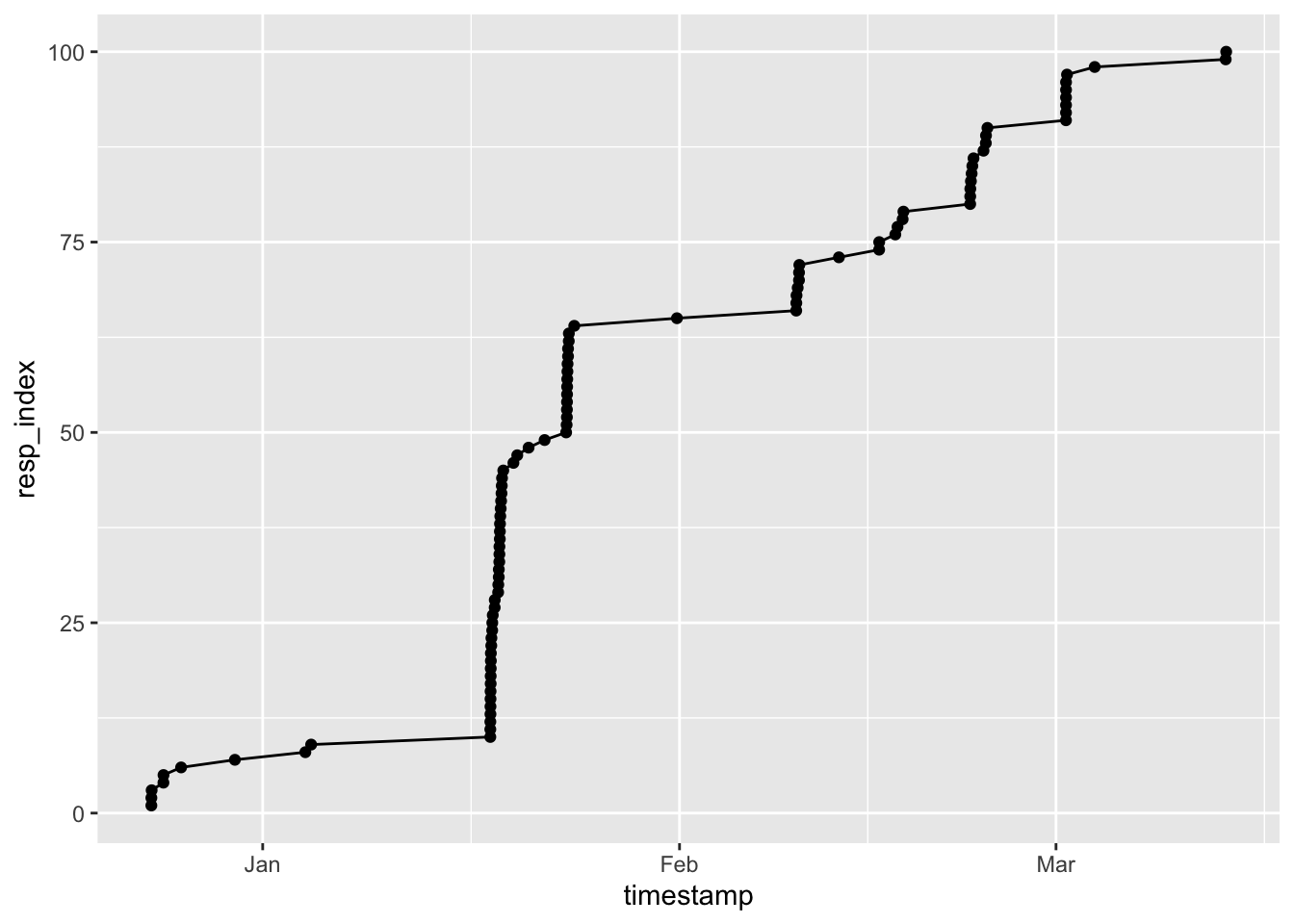
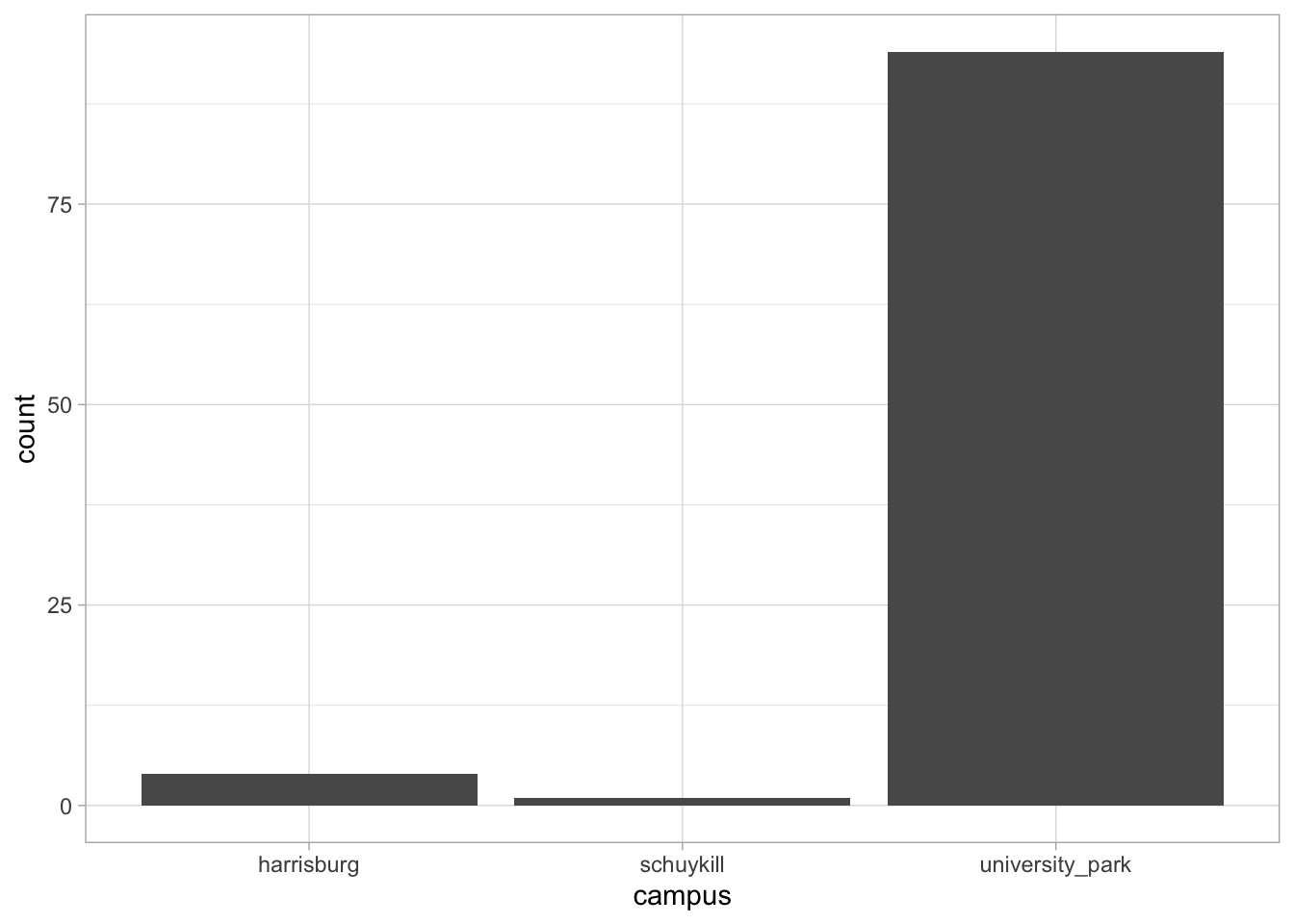
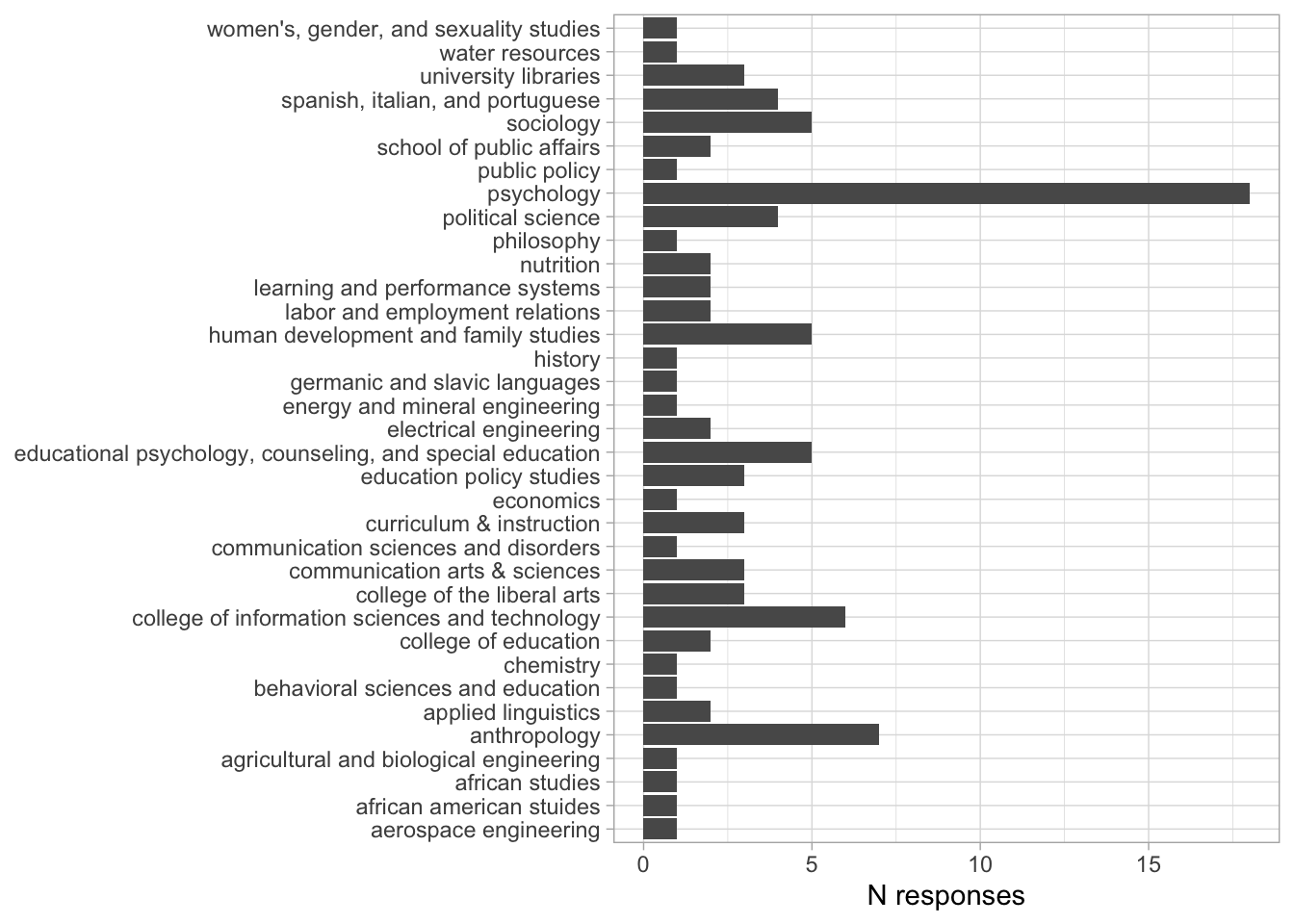
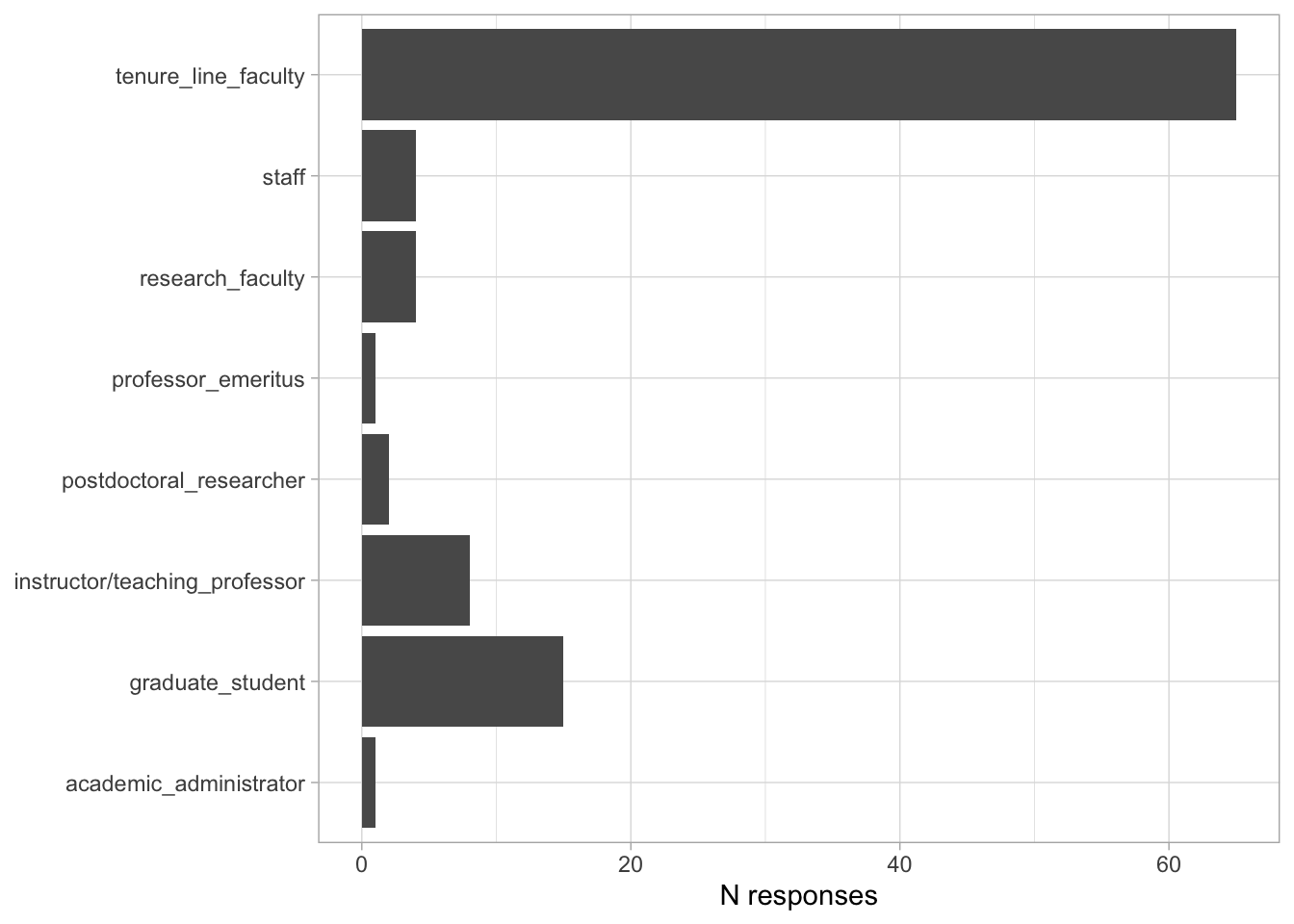
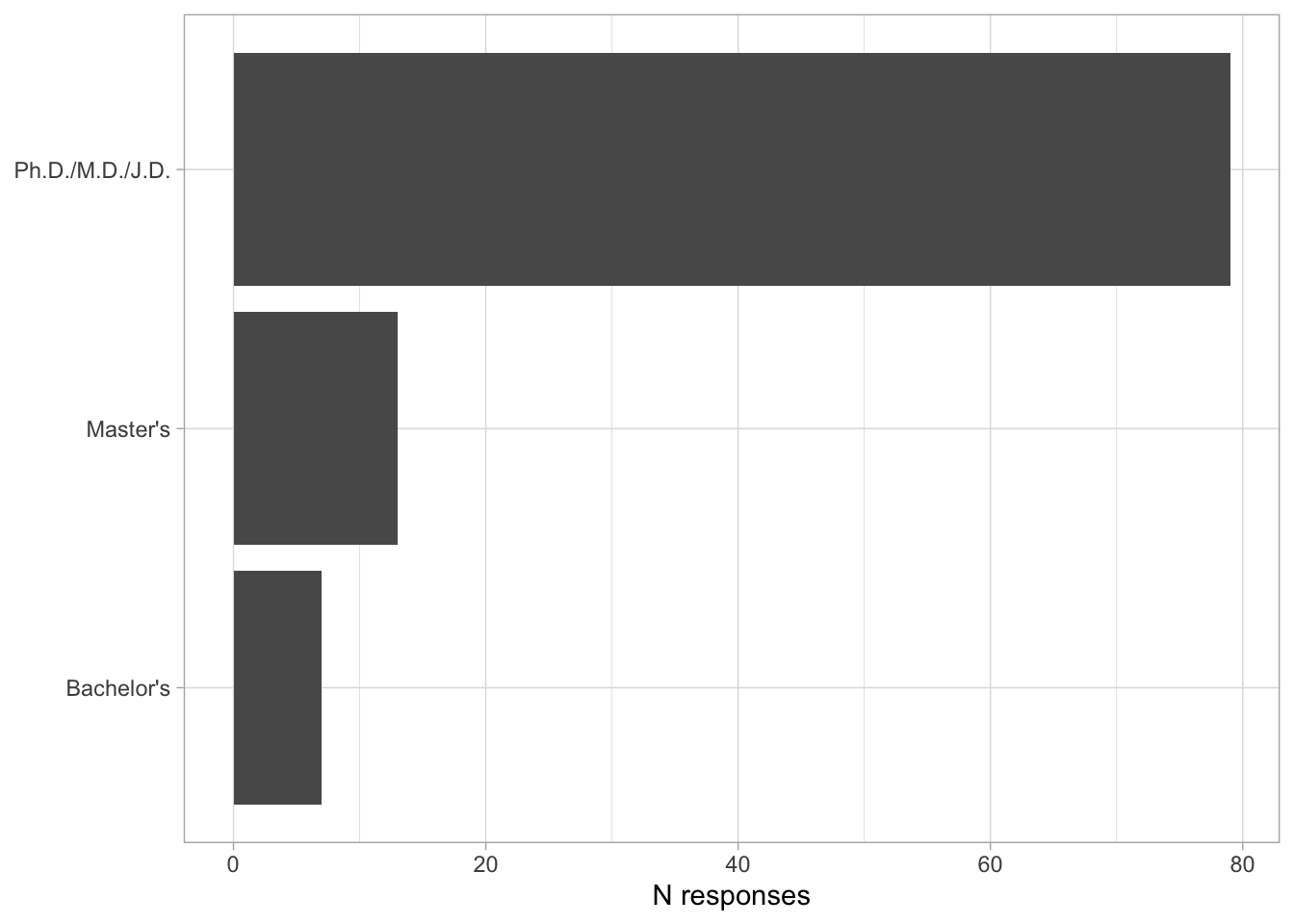
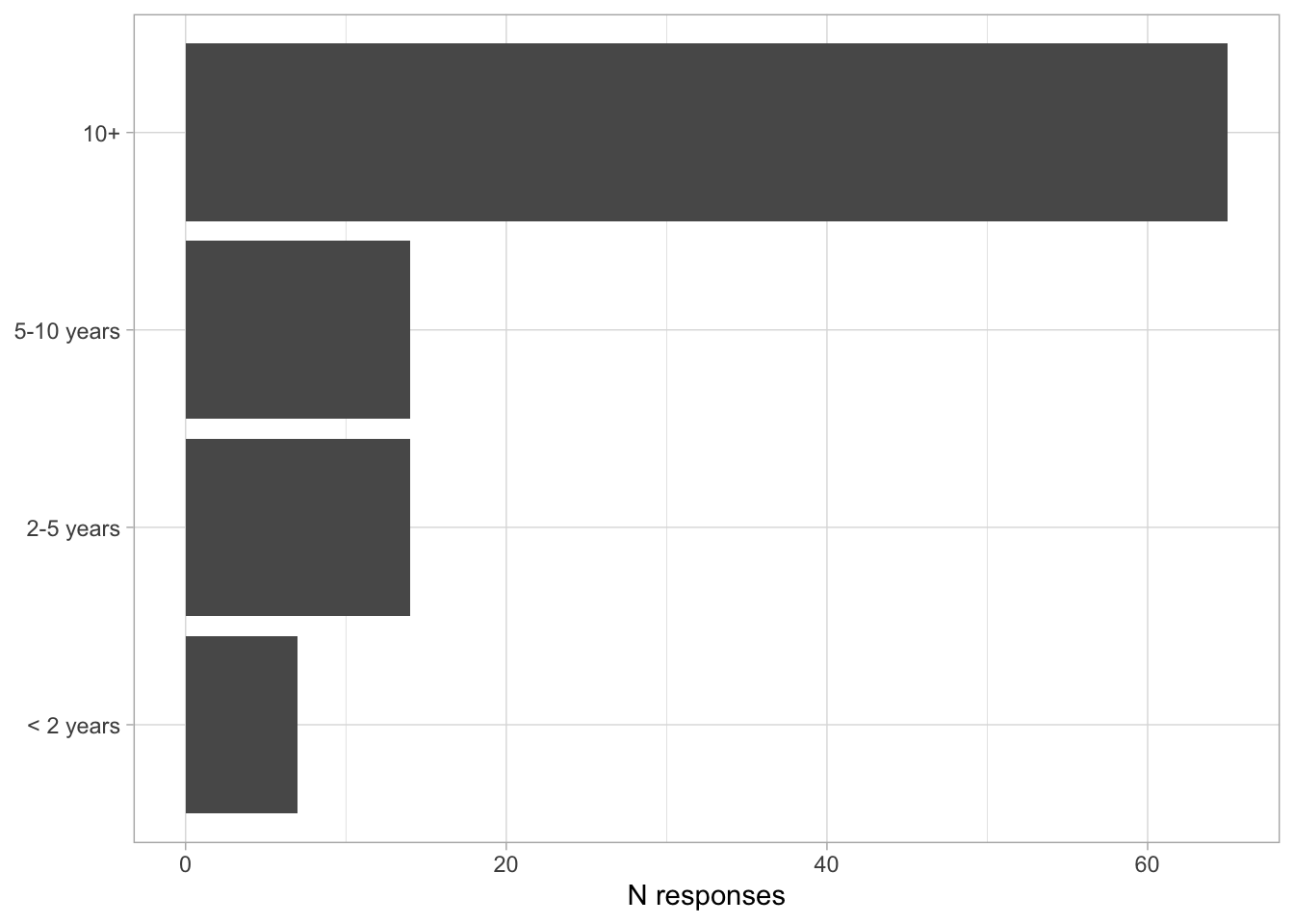
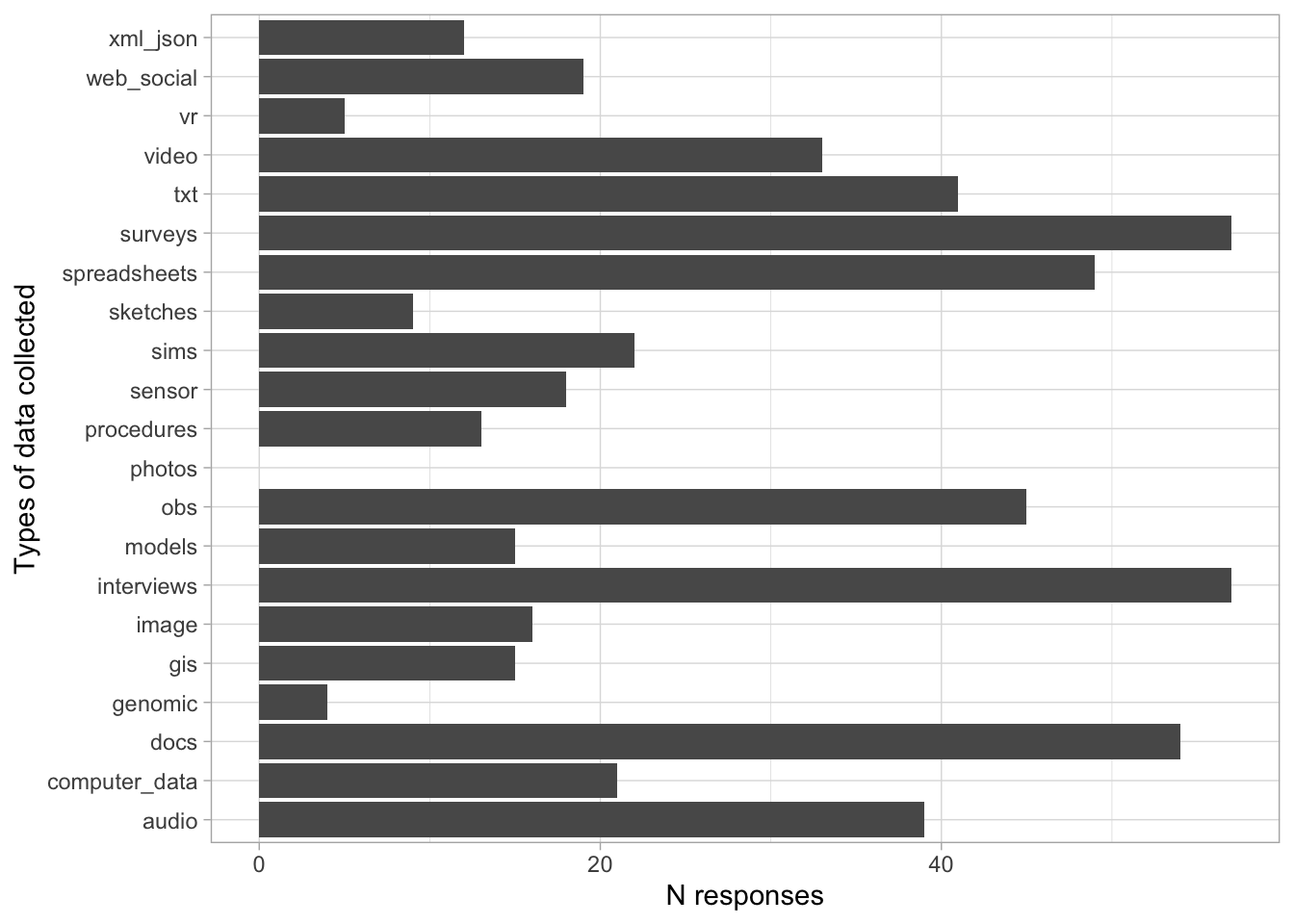
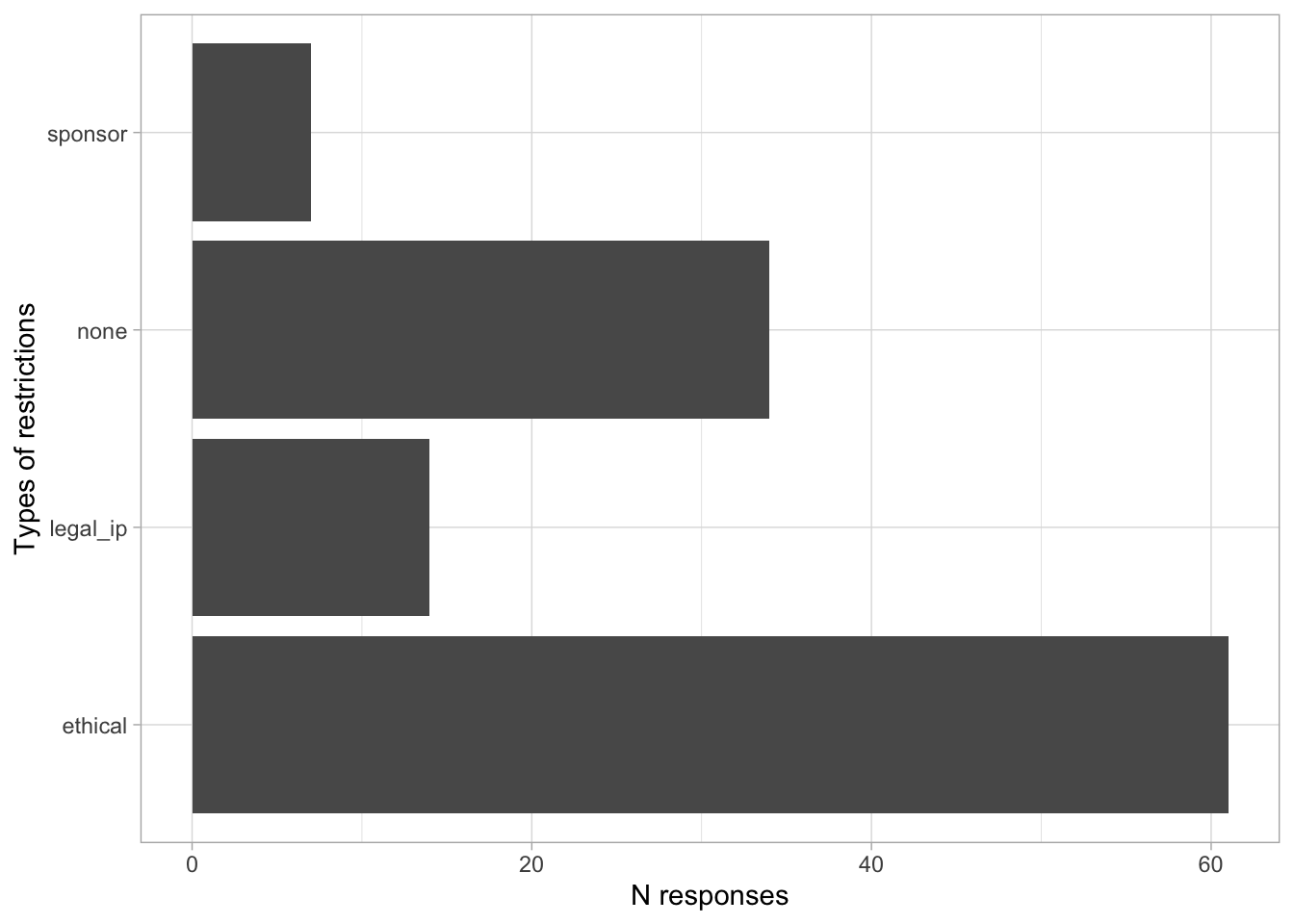
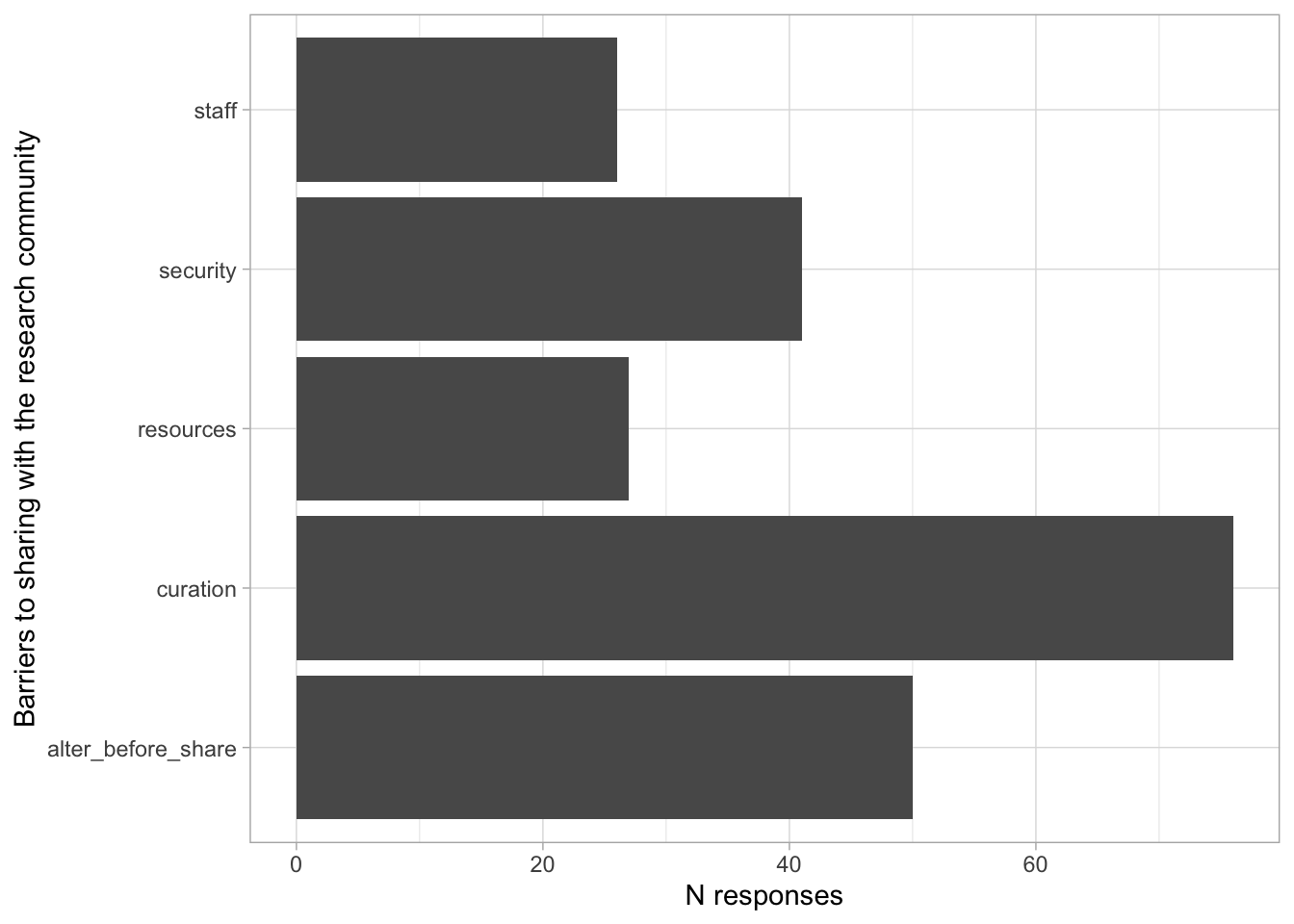
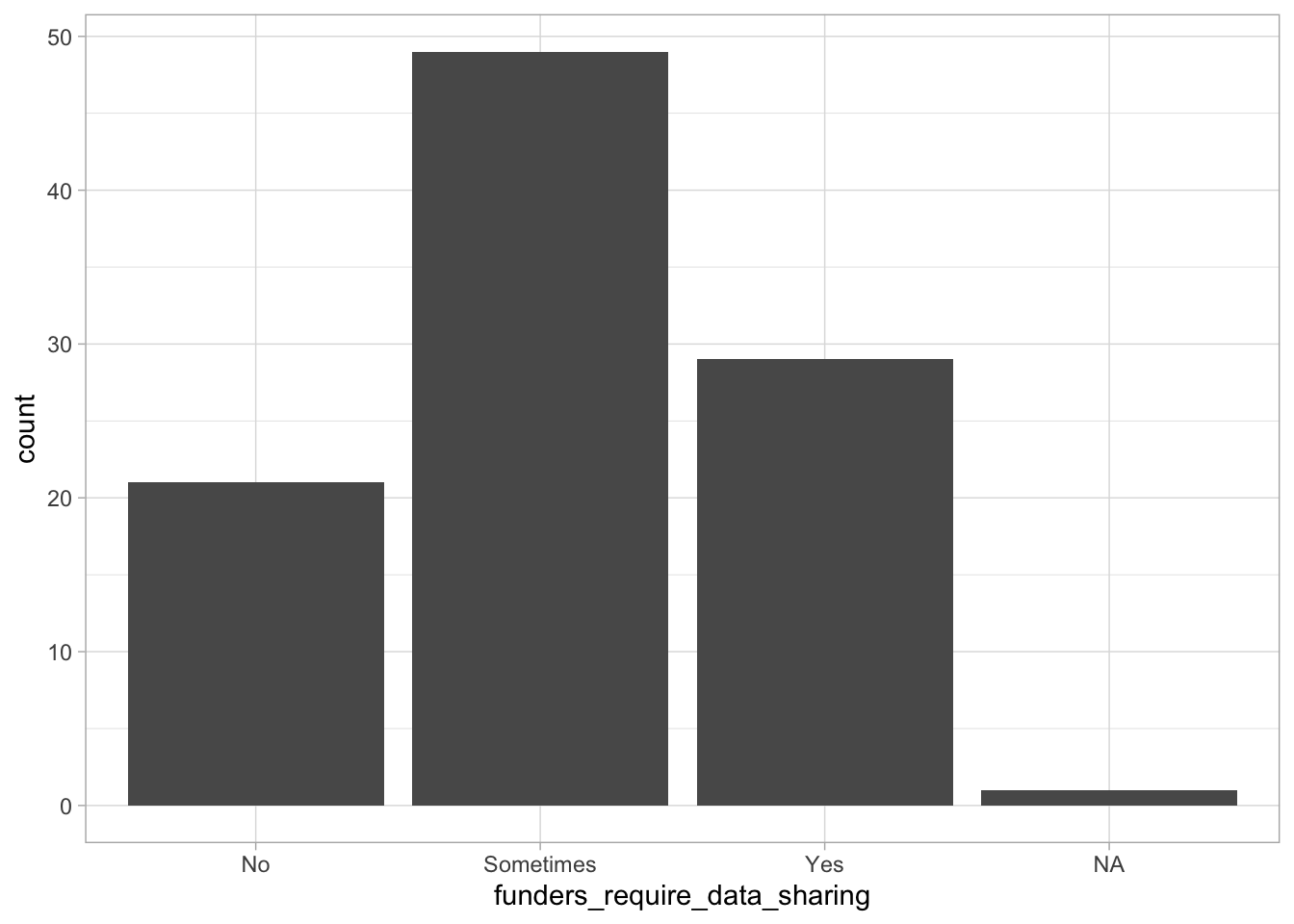
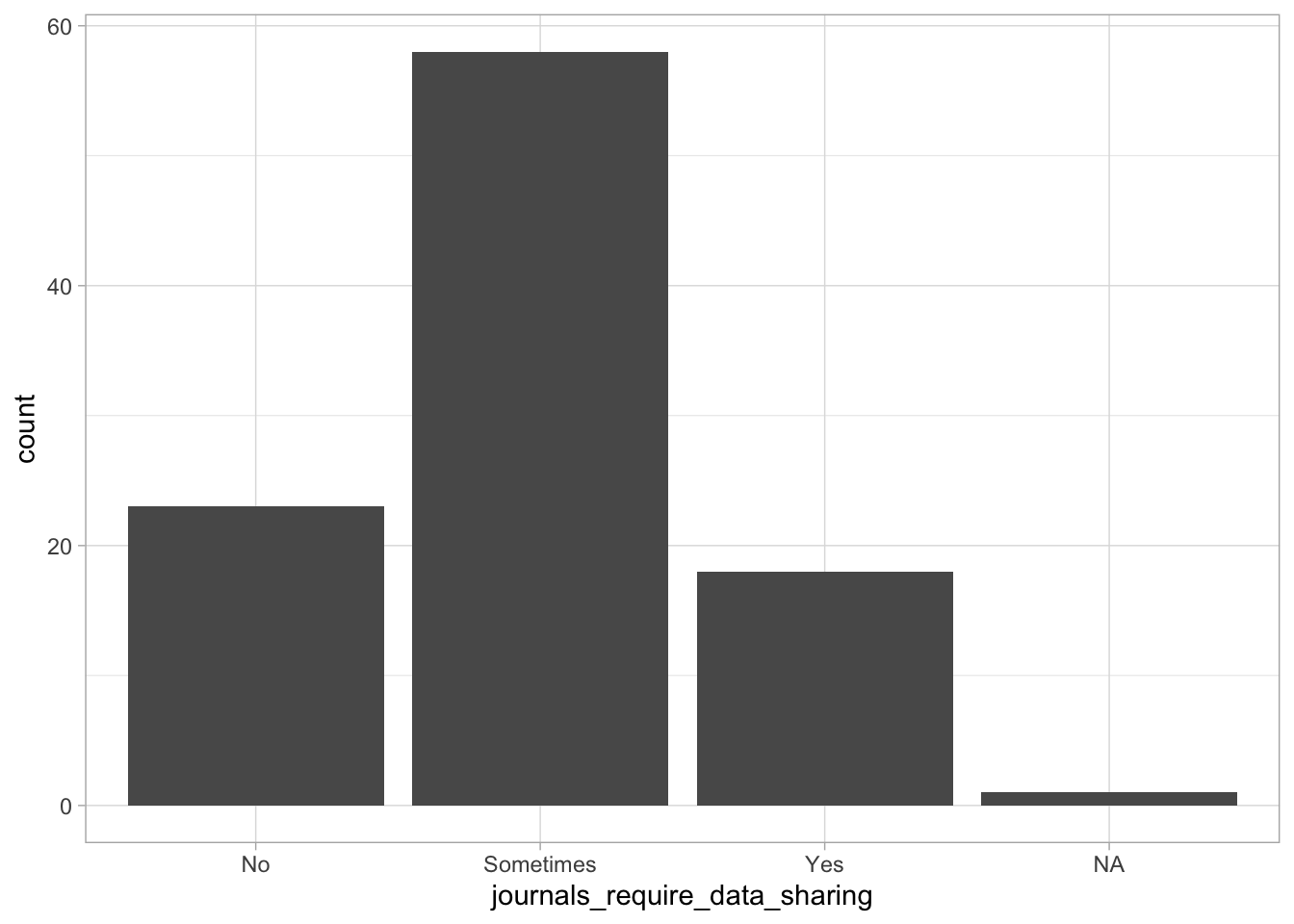
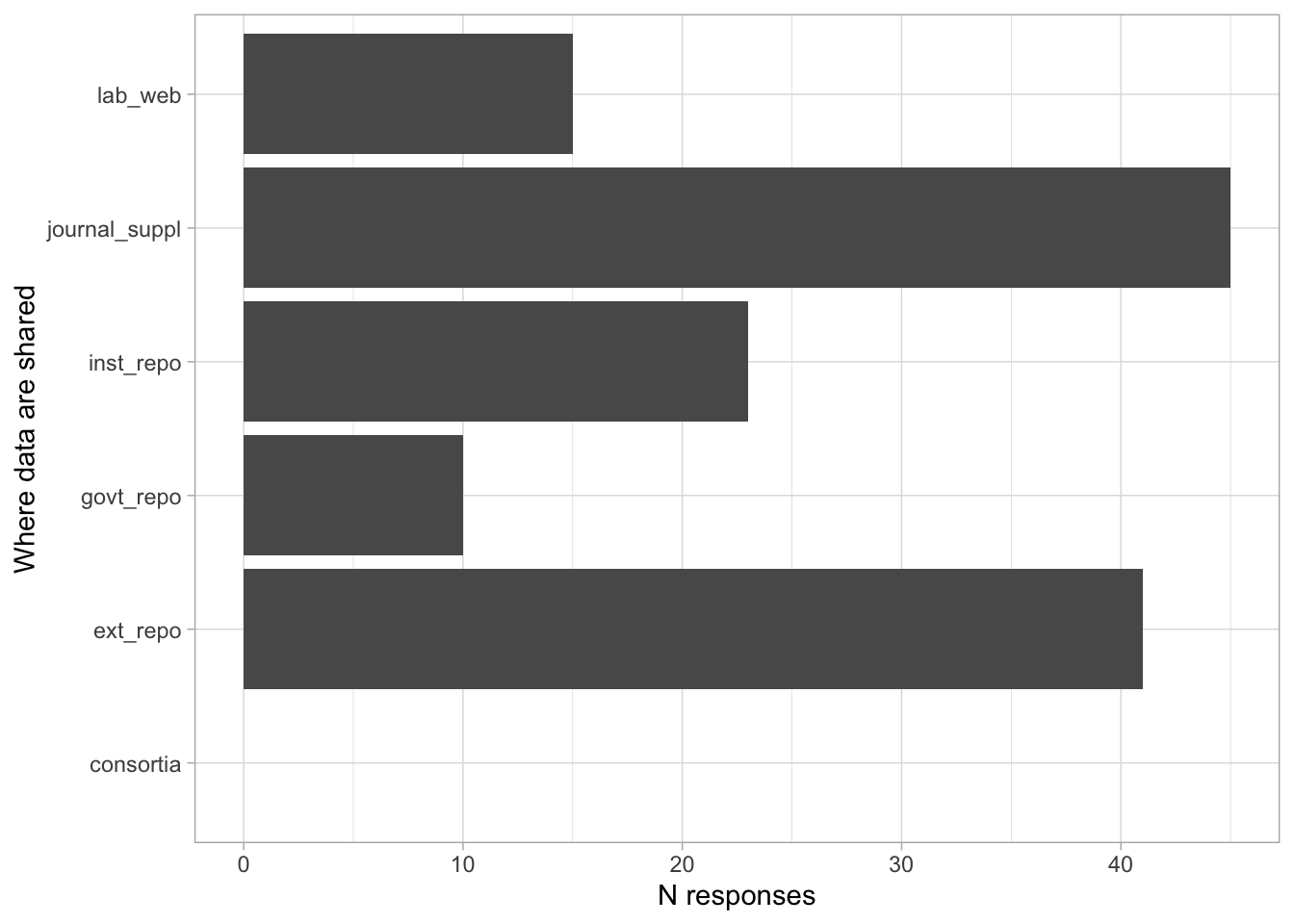
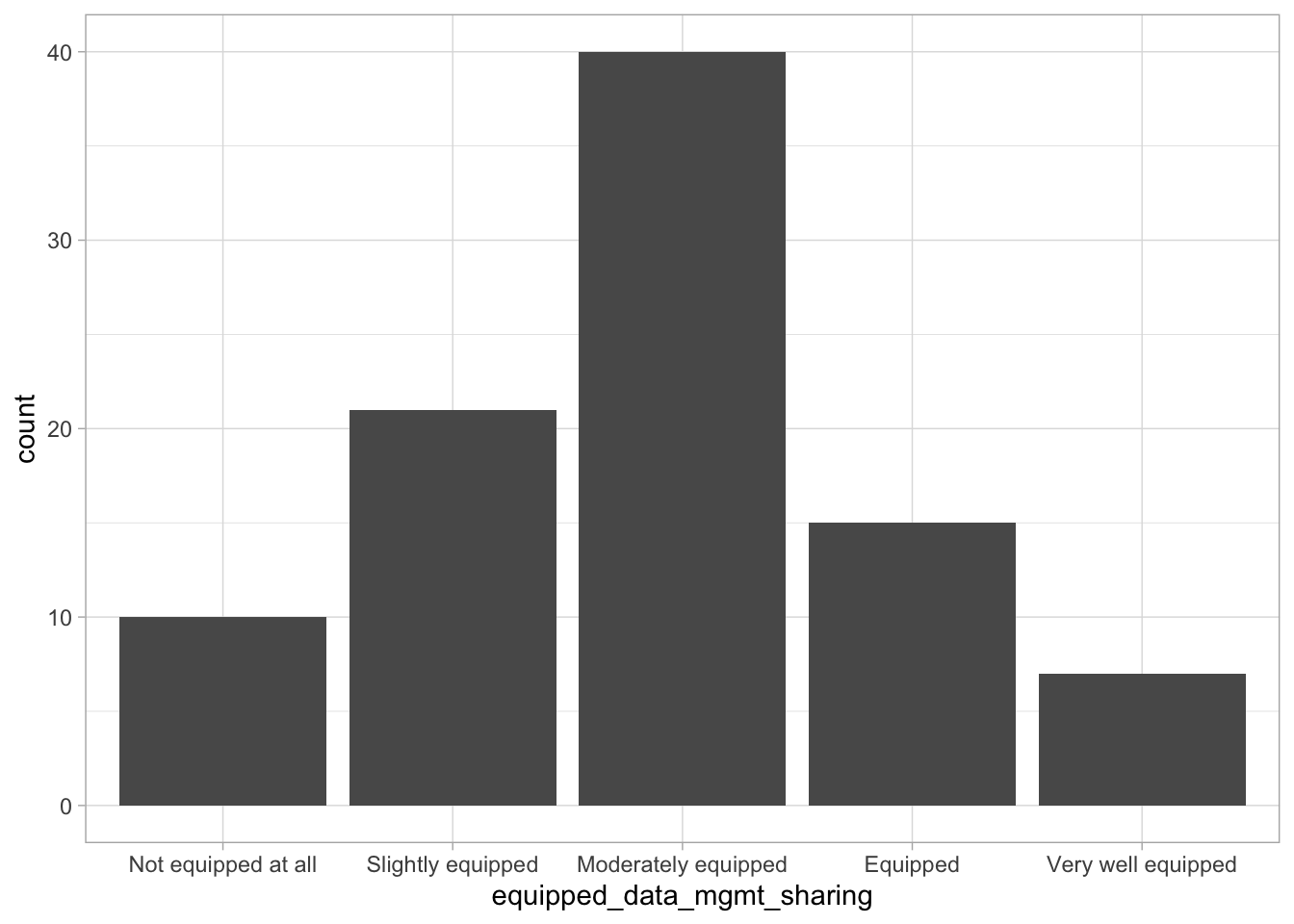
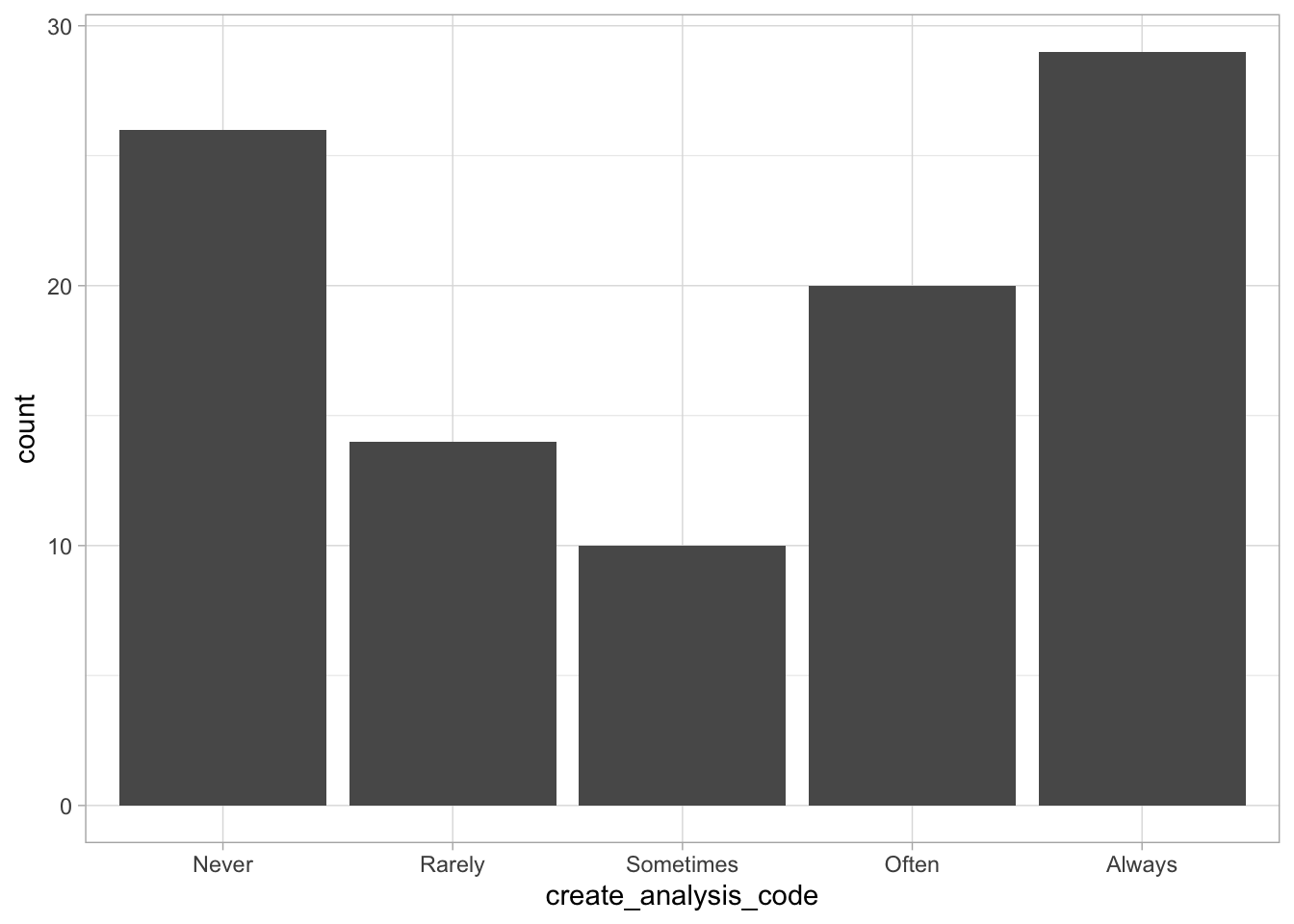
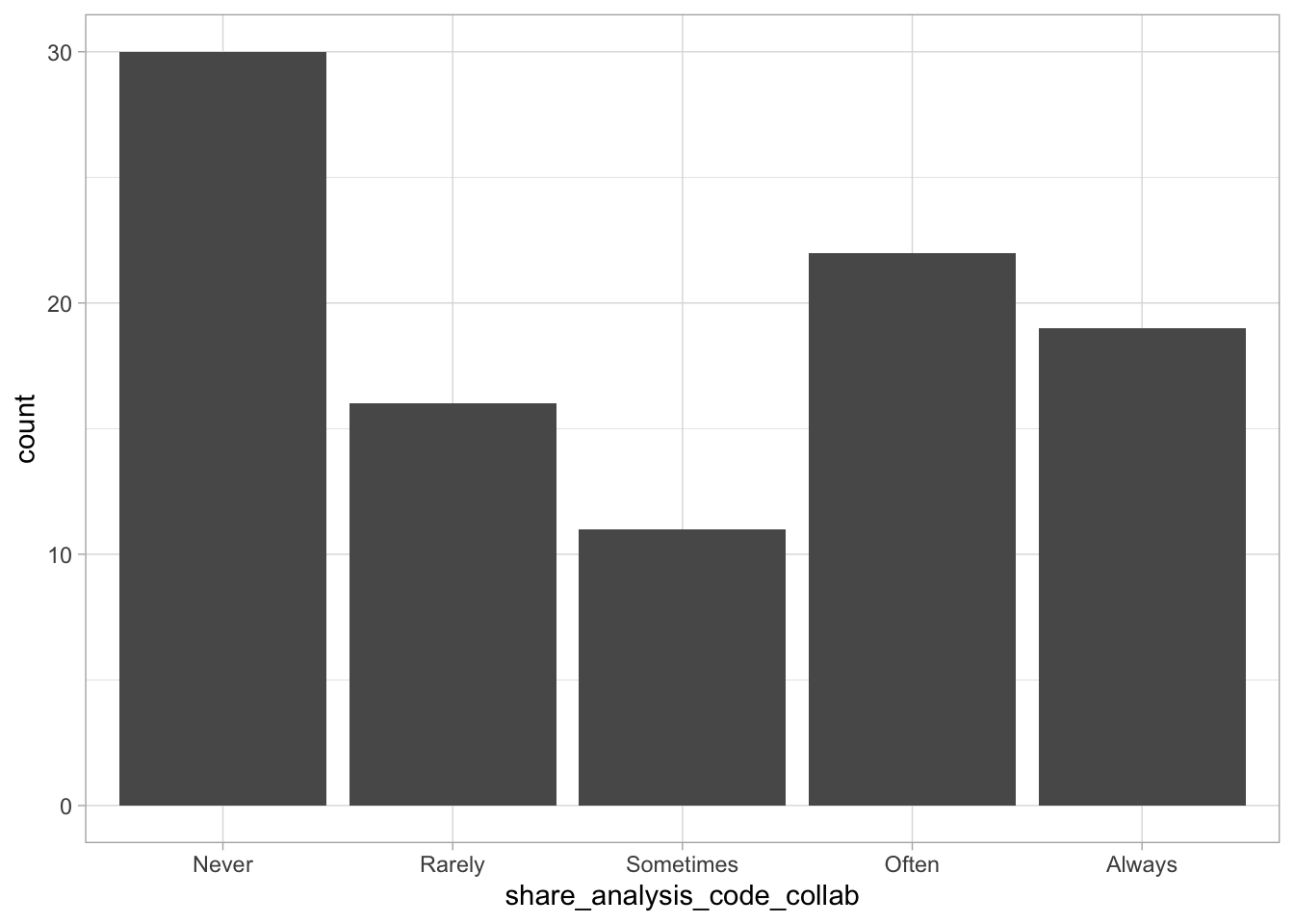
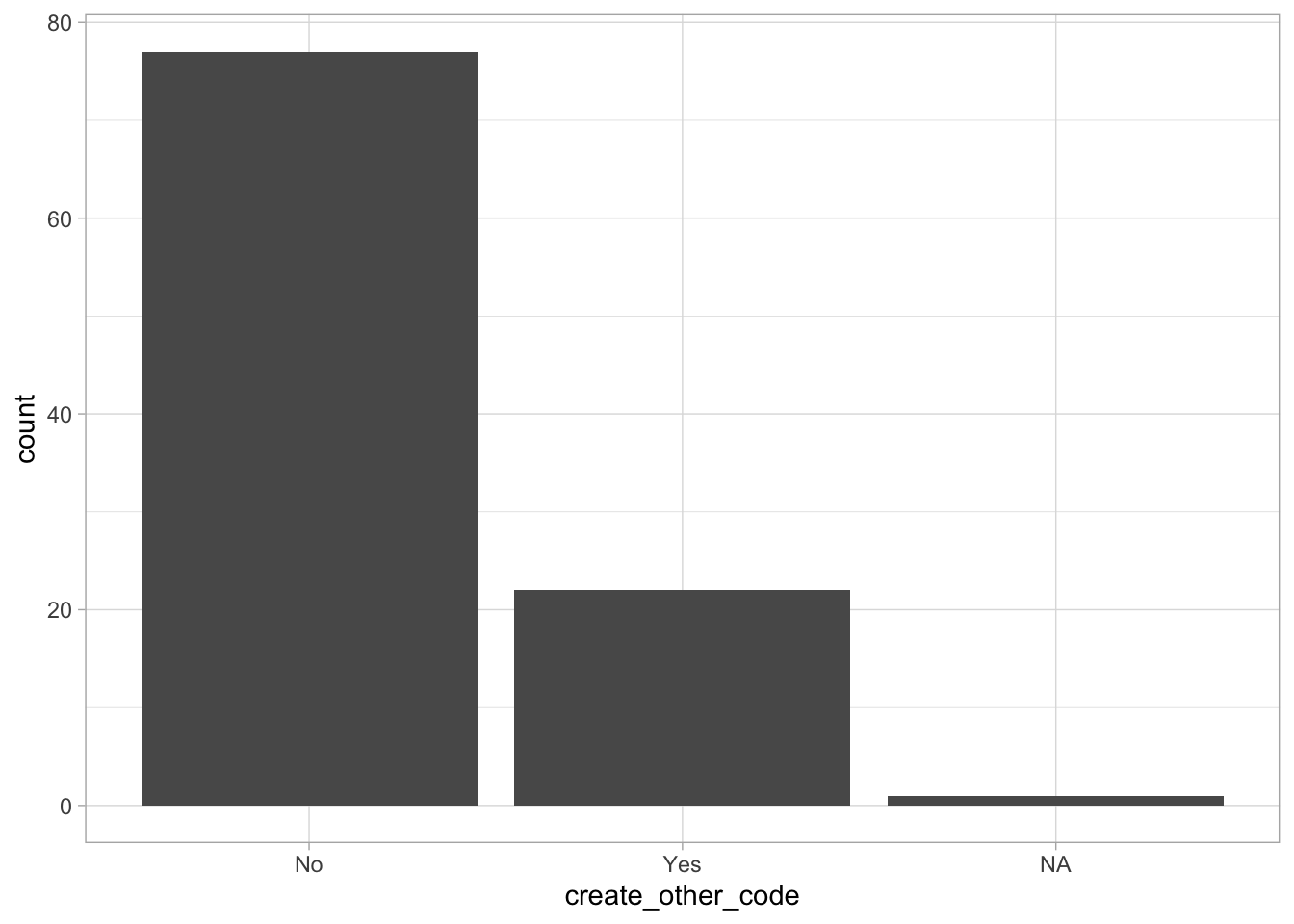
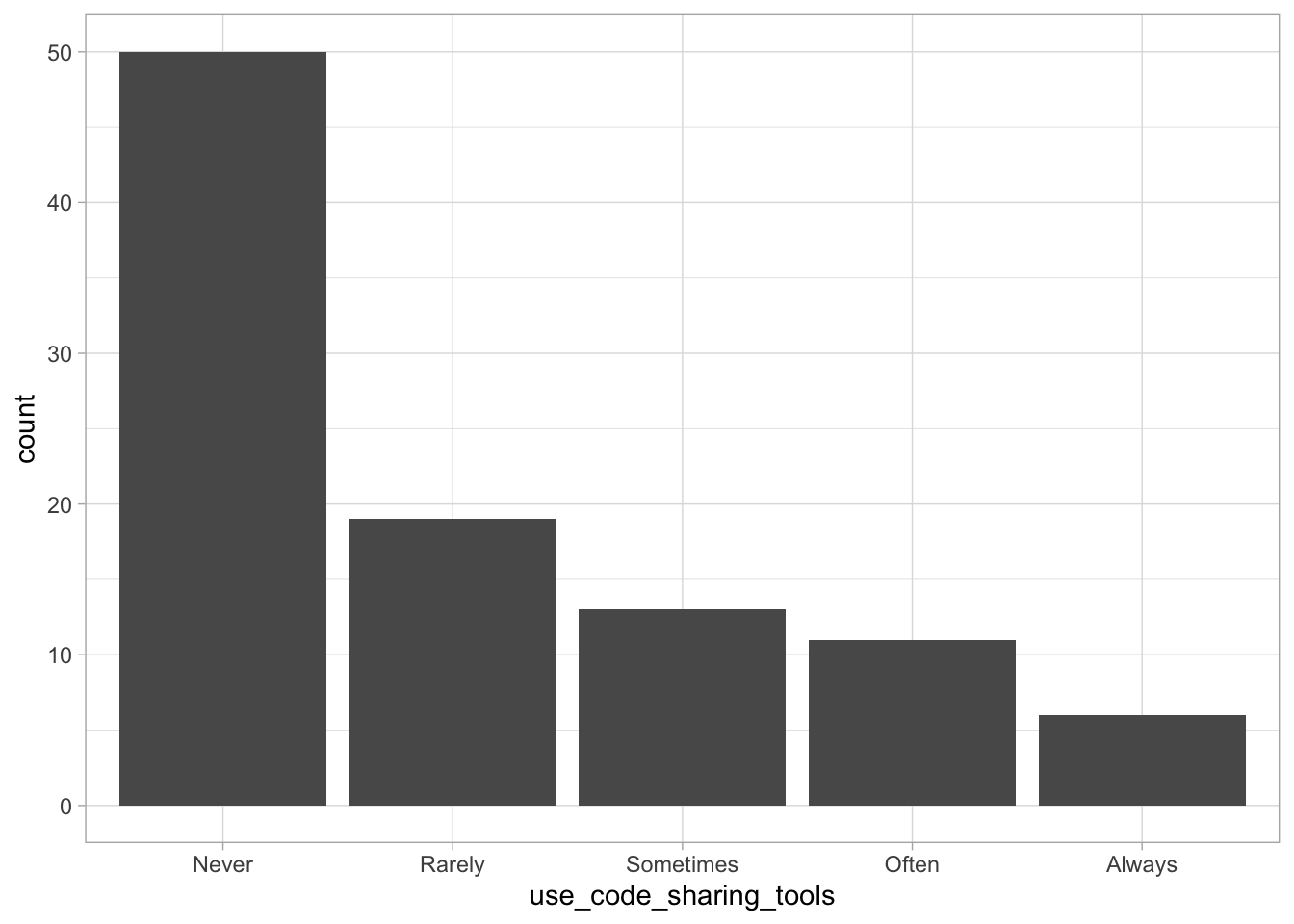
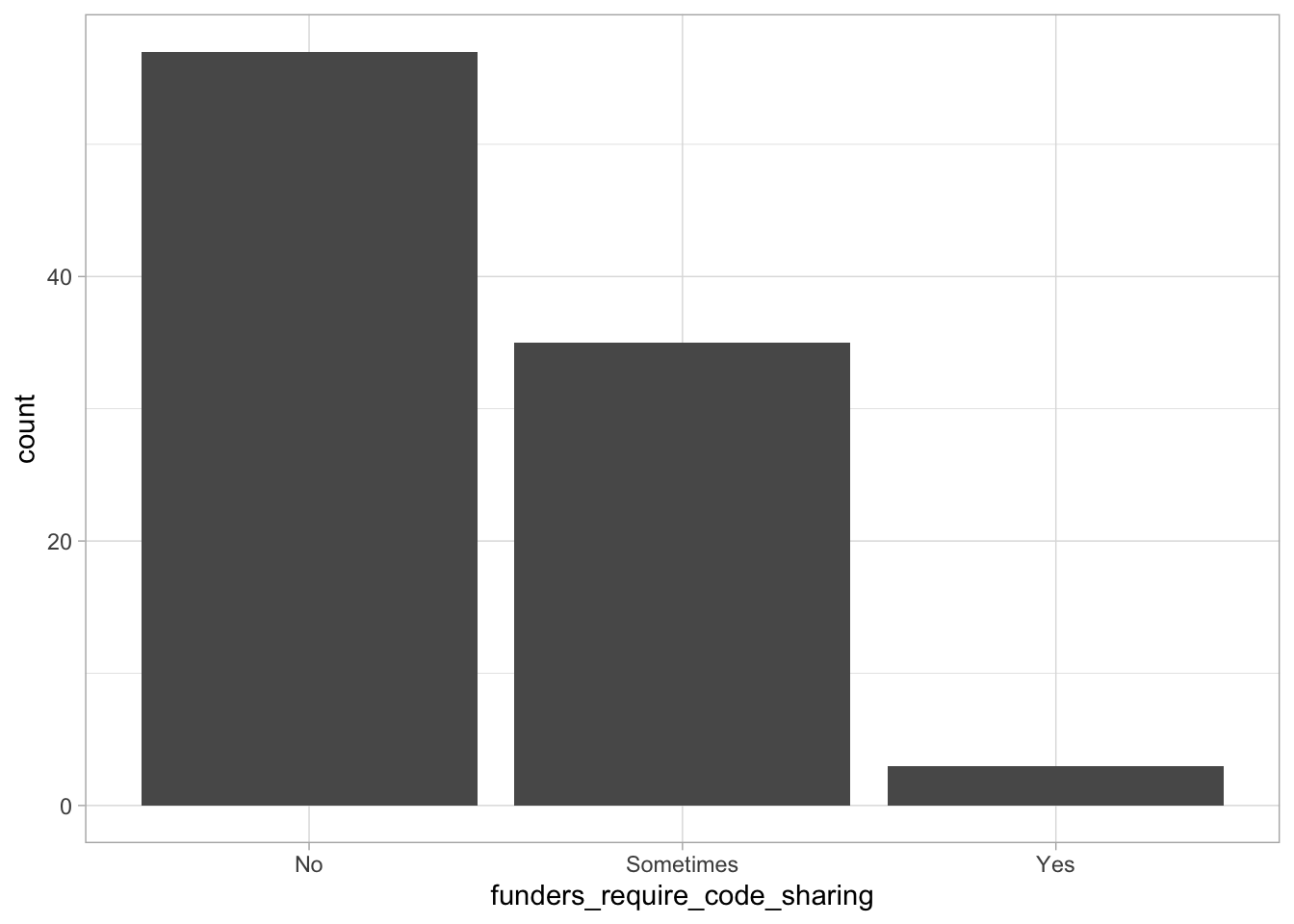
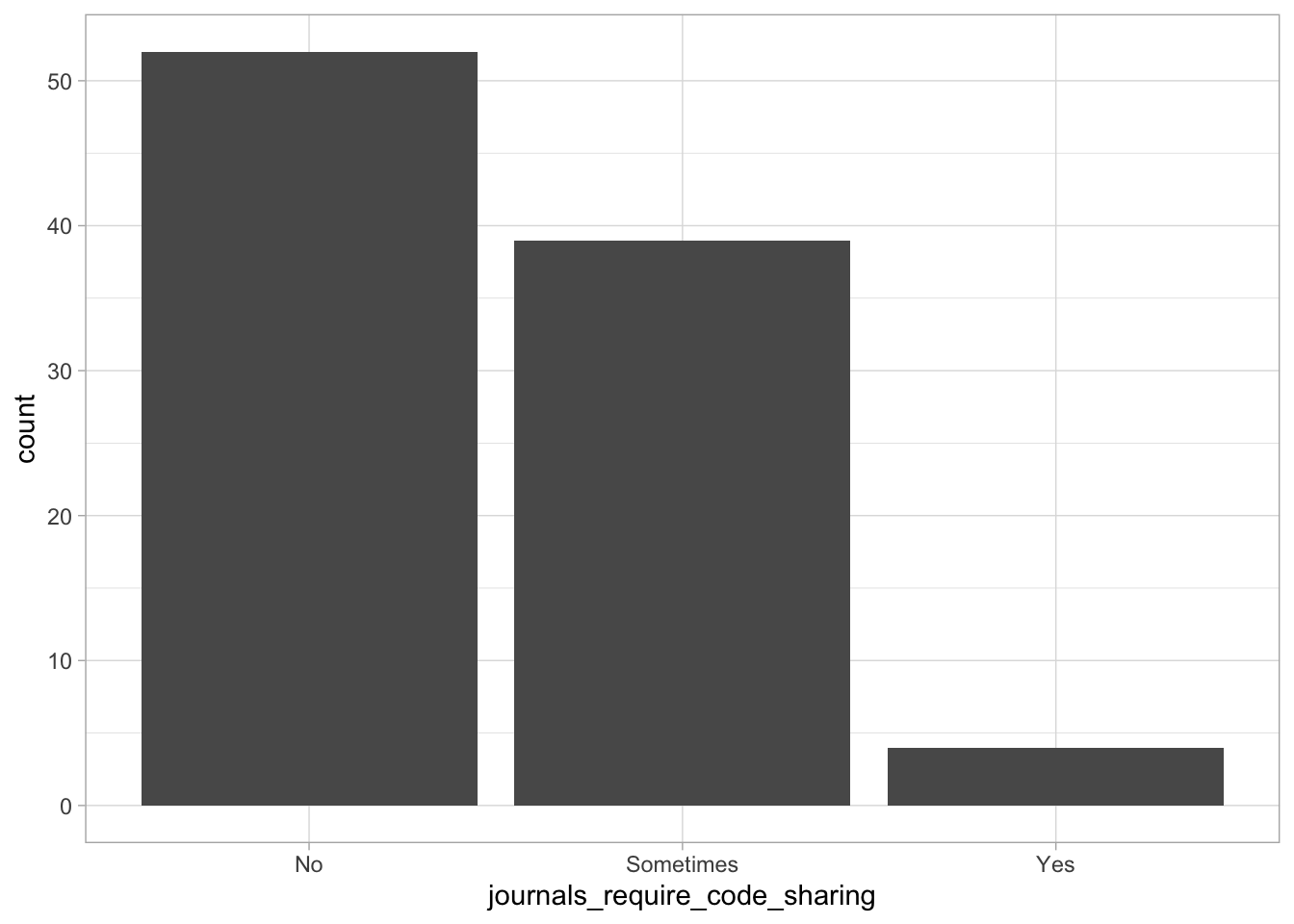
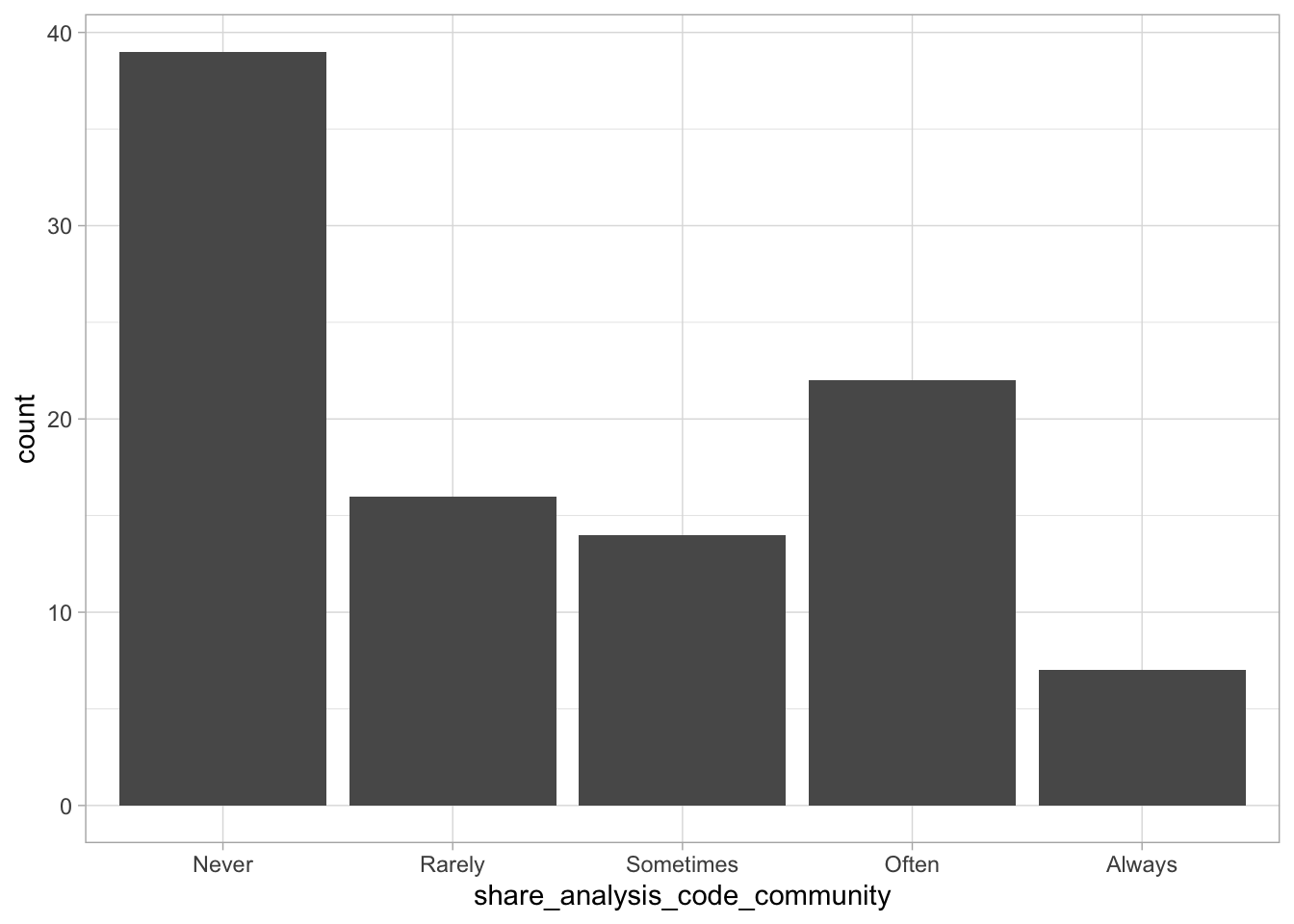
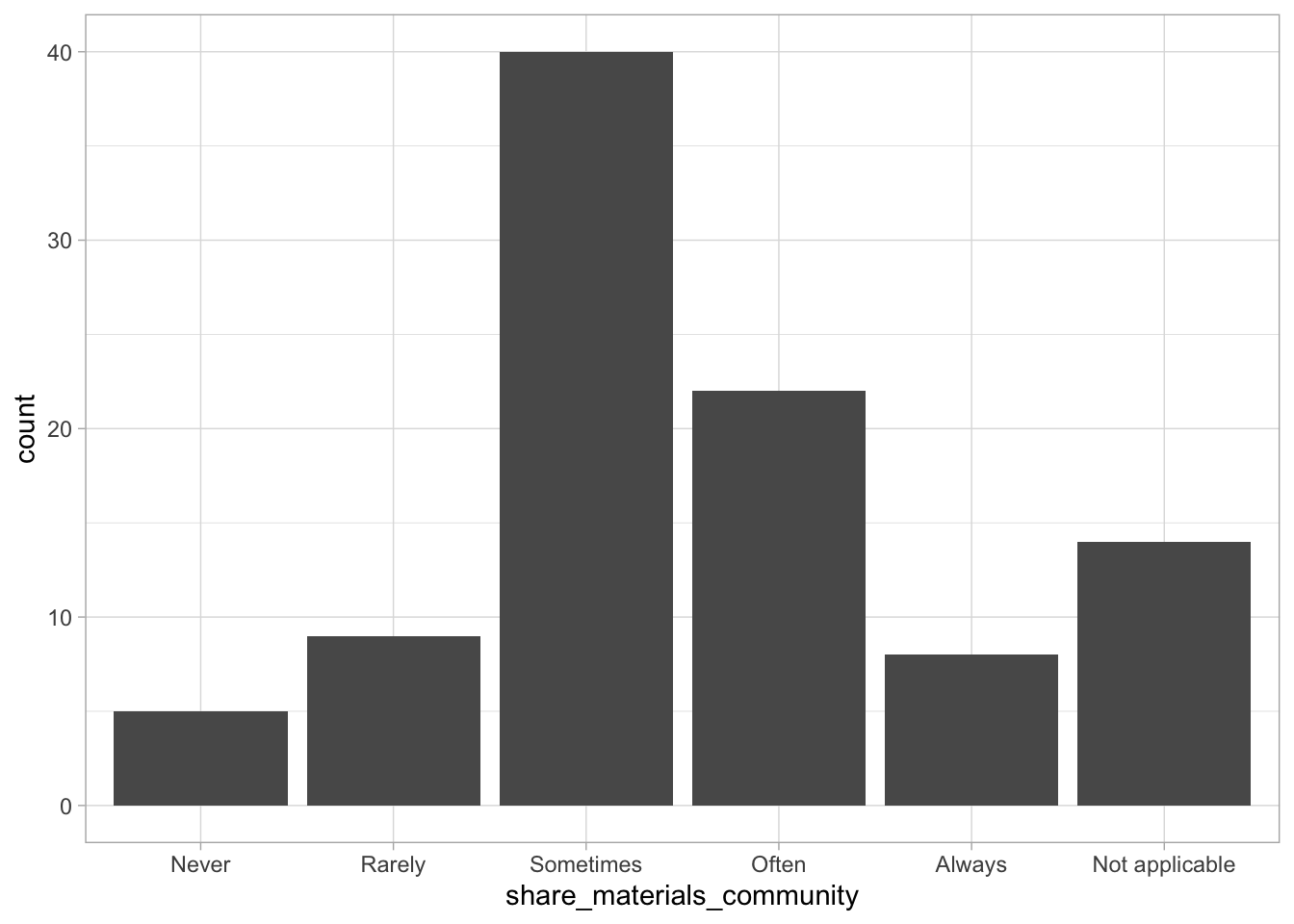
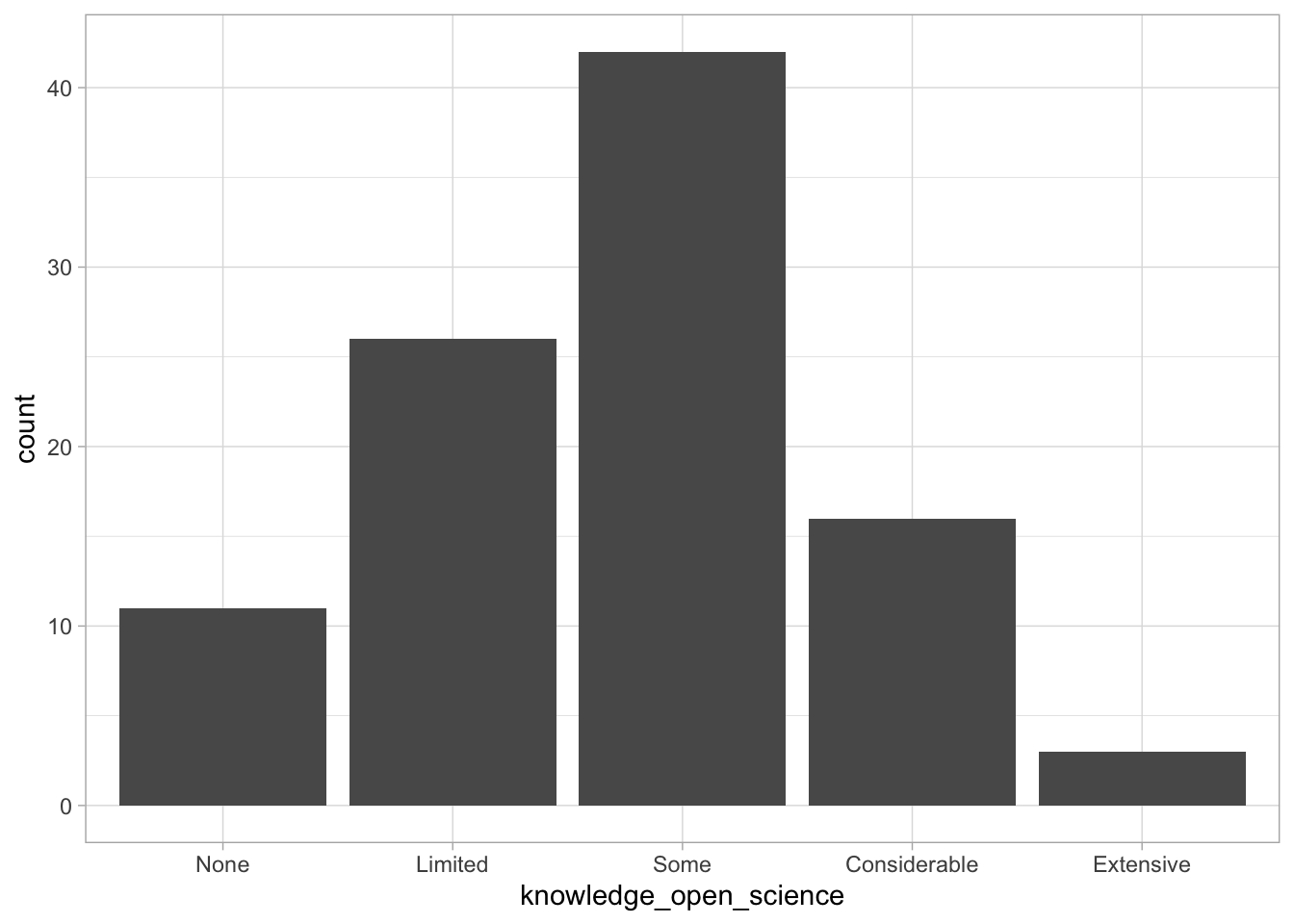
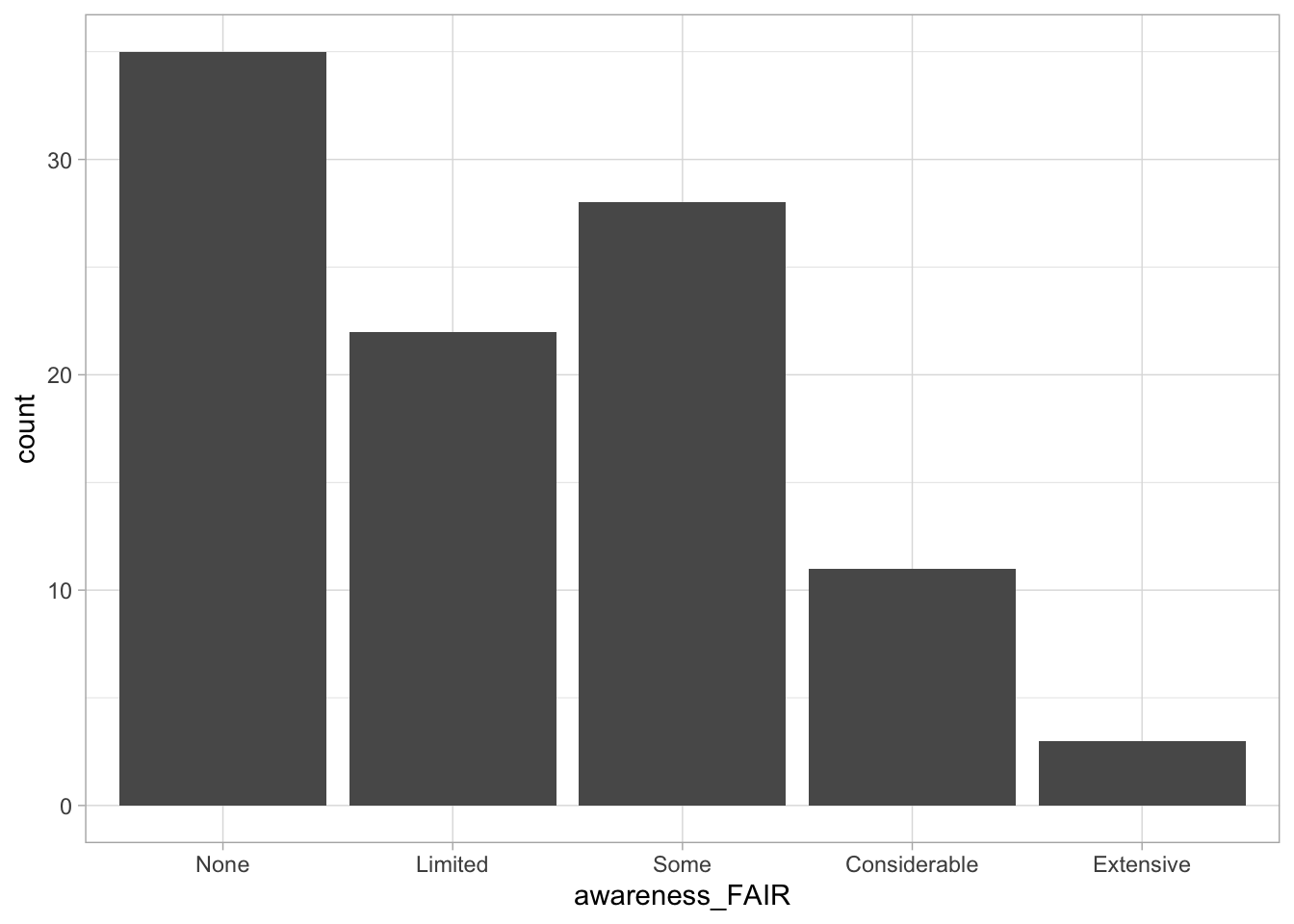
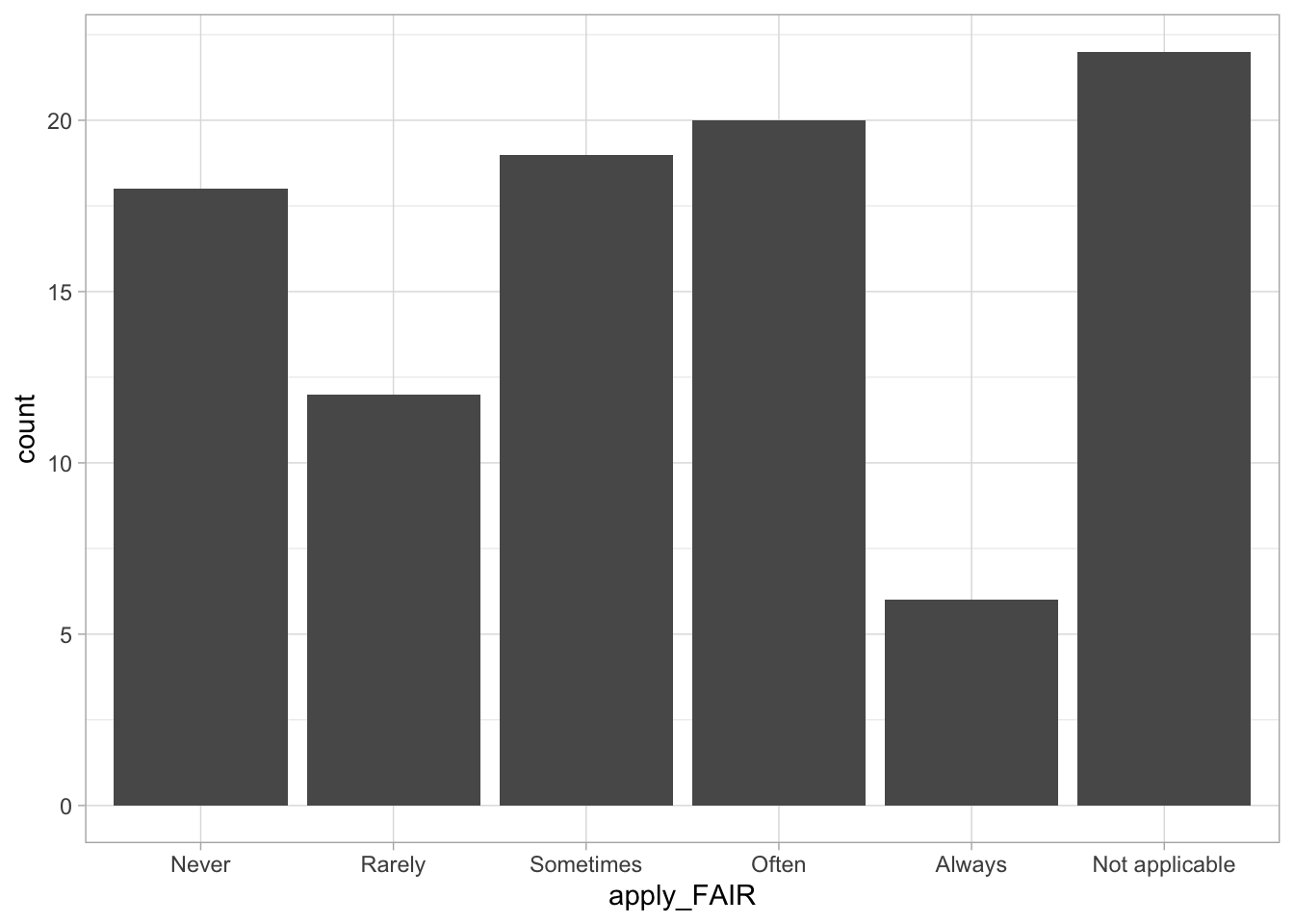
Comments